A little over two years ago, after an exhausting day of packing up our apartment in Brooklyn, I turned to my partner and said “Hey,…
Farewell CDL!
Posted in Projects
University of California Curation Center (UC3)
Posted in Projects
A little over two years ago, after an exhausting day of packing up our apartment in Brooklyn, I turned to my partner and said “Hey,…
Posted in Digital Curation, and Projects
Part 2: On practicing what we preach Originally posted on Medium. A few weeks ago I described the results of a project investigating the data management…
Posted in Digital Curation, and Projects
Part 1: What we did and what we found This post was originally posted on Medium. How do brain imaging researchers manage and share their…
Posted in Uncategorized
Building an RDM Maturity Model: Part 4 By John Borghi Researchers are faced with rapidly evolving expectations about how they should manage and share their data,…
Some of the most influential research tools of the last century were created to ensure the quality of beer and extrapolate the results of agriculture…
As part of an effort to enhance transparency in biomedical research, the National Institutes of Health (NIH) have, over the last few years, announced a…
At the very beginning of my career in research I conducted a study which involved asking college students to smile, frown, and then answer a…
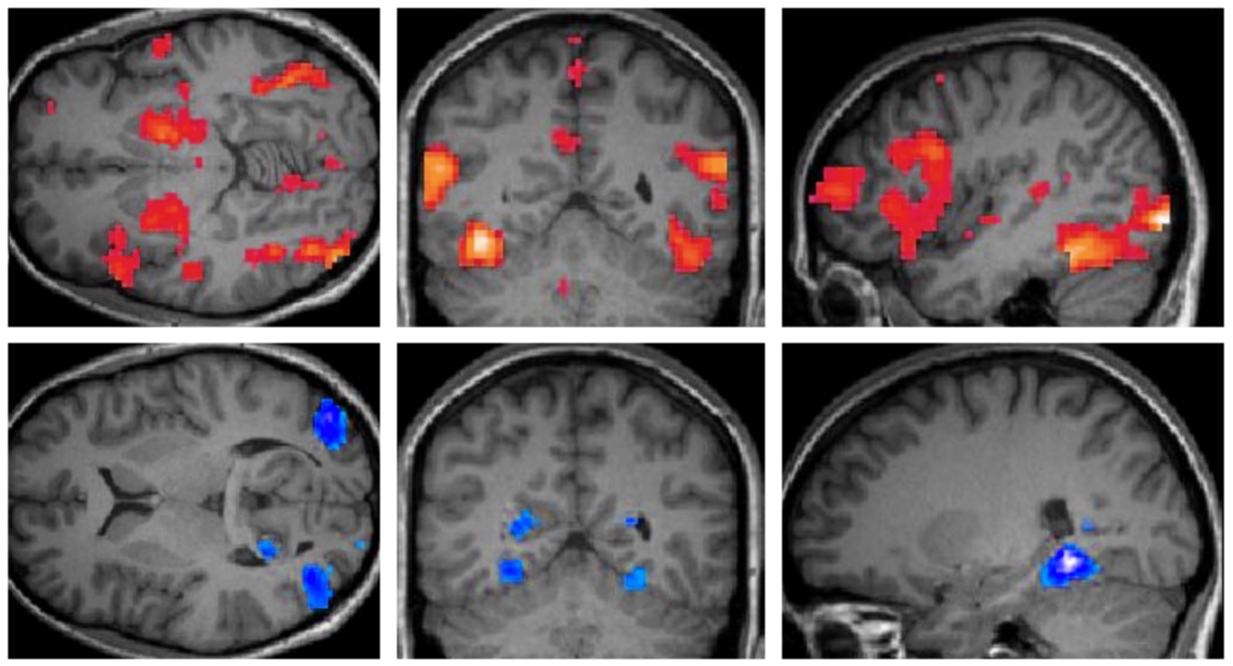
If you spend some time browsing the science section of a publication like the New York Times you’ll likely run across an image that looks…
Back in May, almost 30 librarians, researchers, and faculty members got together in Portland Oregon to learn how to teach lessons from Software, Data, and…
It has been a little while since I last wrote about the work we’re doing to develop a research data management (RDM) guide for researchers.…