(index page)
UC3 New Year Series: Data Management Planning in 2026
Welcome to the second post of UC3’s New Year blog post series, where different services of UC3 take a look at the coming year. If you haven’t already read it, check out the first one on digital preservation.
Over in the world of Data Management Planning, we’ve got a lot of exciting work this year to share!
DMP Tool Rebuild
Our main project continues to be working on the rebuild of the DMP Tool. While we initially hoped to have it ready early this year, we’re now targeting the summer of 2026. This gives us more time to make sure it’s at a high level of quality, and also releases it at a time that will hopefully be less disruptive to people who teach classes using the DMP Tool. There’s a chance it will take longer than the summer though – we’re focused on quality over speed.
We’ve done 3 rounds of user testing so far on the site, and each time has given us a lot of valuable information. We’ve gotten a lot of positive feedback about new features we will be offering, such as alias email addresses, adding collaborators to templates, a revamped API, and much more. Other changes, though, have caused some confusion for people used to the current tool, and through testing we have found opportunities to improve the workflow and usability of the new site. These are the types of changes that mean the rebuild will take longer than initially planned to complete, but we think are worth the time to get right.

To keep updates about the rebuild in one place, we have a Rebuild Hub page on our blog. We’ll keep this page up to date with the latest information about the release date, FAQ, status updates, and more. We plan to make posts leading up to the new release showing the major changes and giving guidance to make the transition as seamless as possible. If you’d like to help with testing at any point, please sign up for our user panel to get invitations to future feedback sessions.
As we’ve said before, we’re limiting updates to the current tool so we can focus our limited resources on the rebuild; but of course we also want to keep the tool live and helpful during the transition. We’re fixing any major issues that come up, such as keeping it up to date with new ROR API and schema, and addressing user tickets as quickly as possible. We are trying to keep funder templates up to date as well, but the frequency of new information and potential changes has made it difficult to perfectly capture all updates to federal guidelines. We want to make sure we have the most relevant information possible on the tool without changing templates too often (as that can lose organization guidance), so we’ve been collecting updates from our Editorial Board members for a template release in the near future. If you see any instances where a template in our tool does not match a funder template, please reach to us by email so we can get it corrected.
Get Involved with API Integrations
With our rebuild is coming a complete revamped API to take advantage of our new machine-actionable functionality. We’re currently looking for partners that would like early access to our new API in order to develop new integrations for our rebuild. Our goal is that the new API can do anything the user interface can do, which means the sky (or more relevant, the cloud) is the limit for possible tools. If you’ve been wanting to connect to our API for some sort of automation that our current API did not offer the capability for, we’d love to hear from you. You can hear more about past pilot integrations and how to work with our API at this recording of our webinar from the Machine-Actional Plans pilot project. We’ll be following the common API standard being developed with the Research Data Alliance, meaning many integrations with our tool should work for other DMP service providers as well. If you have an idea for an integration you’d like to build on our new API, please reach out to dmptool@ucop.edu!
Matching to Published Research Outputs
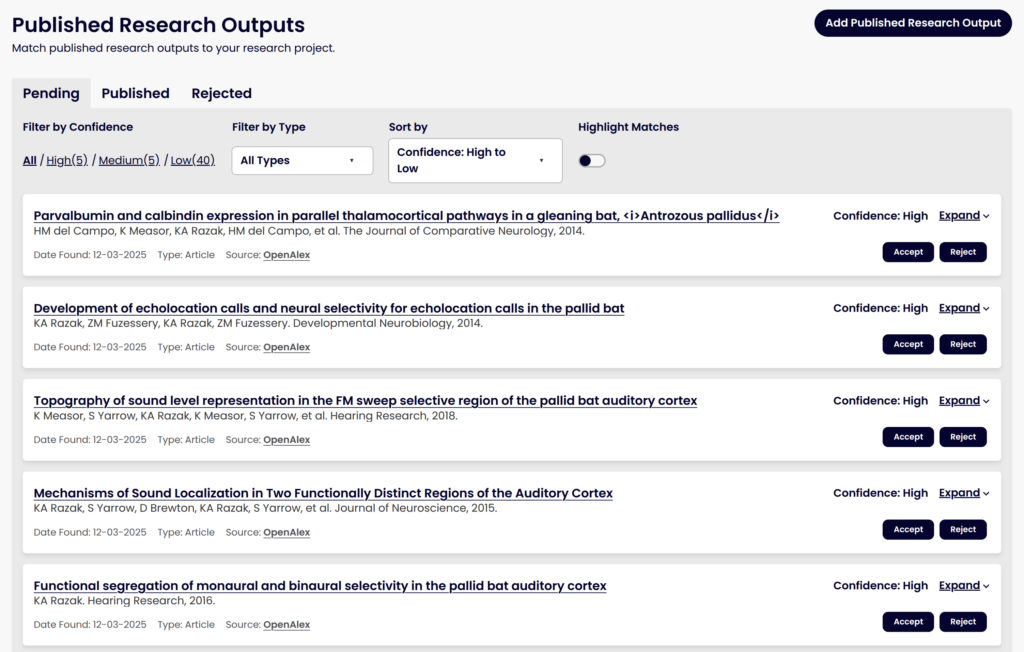
We’ve talked before about a major project to use machine learning models to help match DMPs to their eventual research outputs, like datasets and software publications, to help make data from published DMPs easier to find and re-use. This work has continued and we plan to release it with the rebuilt DMP Tool. Since our last update, we’ve made some significant steps towards this goal, including:
- Moving the infrastructure onto our own servers to prepare for integration into the DMP Tool
- Adding new sources of data, such as grant award pages that list published outputs
- Getting the normalized corpus into OpenSearch to aid us in the matching process
- Expanding our ground truth dataset of true matches and non-matches to help test our matching algorithm
- Utilizing a Learning to Rank model that will improve over time as it learns from accepted and rejected matches
- Building out the user interface for how users will see potential matches and accept or reject them
Improvements we plan to work on over 2026 include:
- Adding in related outputs based on accepted outputs (i.e., finding matches to any Accepted works in addition to matching against the DMP itself)
- Looking at options to improve the matching algorithm, such as vector search with an embedding model
- Working with the COMET team on tooling that can extract award IDs from published outputs, which will improve the quality of matching to DMPs that include an award ID
We’re excited for people to get to use this tool with the rebuild and start accepting and rejecting potential matches so we can learn from this and improve the matching algorithm further over time. People will also be able to manually add DOIs as research outputs, like they can on the current tool, which will also help train the model over time on what we missed as potential matches. This will be available for all DMPs that have been published, i.e., registered for a DMP ID. Accepted works will be added to the metadata for the plan as related identifiers.
DMP Chef
Another exciting area we’re exploring is the use of generative AI to assist in writing Data Management Plans. We’ve partnered with the FAIR Data Innovations Hub to work on the DMP Chef, a project to explore using large language models (LLMs) to draft DMPs. Our goal is not to take away the key decisions in data management planning from a researcher, but instead to simplify the process as much as possible by asking a few critical questions, combining that responses with funder requirements that need to be met, and using those to produce a draft of a DMP for their review and edits.
We have promising early results, with both automated statistics and human evaluations showing the LLM-drafted DMPs can be comprehensive, accurate, and follow best practices. Commercial models are performing better than the open-source models, but since we want to remain open-source, we’re looking at ways to improve the open-source models through additional retrieval augmented generation and other options. And we’ll be testing carefully how accurate and helpful the output is, as well as looking at ways to help ensure researchers read and edit the plan as needed, rather than just accept the output right away.
| DMP Source | Overall Satisfaction rating (1-5) | Average Error Count per DMP | Accuracy in guessing LLM vs Human |
|---|---|---|---|
| Human | 3.1 | 7.2 | 65% |
| LLMs (combined) | 3.4 | 4.9 | 43% |
| Llama 3.3 | 2.6 | 7.5 | 70% |
| GPT-4.1 | 4.2 | 2.3 | 15% |
Over the course of 2026, we plan to keep testing and improving this model, starting with NIH and NSF plans. The ultimate goal is a general use model that can be used within the DMP Tool for any funder to get a first draft of either a whole DMP or specific sections a researcher is struggling with. We have a working prototype tool for DMP generation we will use for testing purposes, with integration into the DMP Tool planned for further out. If you’d like to be part of testing out this new tool, please sign up for our user panel.
Thanks for reading about our major initiatives for the year! Keep an eye out on this space for the next post in our series, about our 2026 plans for persistent identifiers.
We are grateful to the Institute of Museum and Library Services, the National Science Foundation, and the Chan Zuckerberg Initiative for each supporting core components of these initiatives.
Working Toward a Common Standard API for Machine-Actionable DMPs
DMP Tool and the Research Data Alliance
Our work at DMP Tool has been shaped from the ground up through collaborations at the Research Data Alliance (RDA). From the earliest conversations about machine-actionable Data Management Plans (maDMPs) to the creation of the DMP common standard and the DMP ID, the RDA has served as the convening space where we’ve found shared purpose, co-developed solutions, and built lasting partnerships with peers across the globe. That same spirit is captured in the Salzburg Manifesto on Active DMPs, which outlines a vision for DMPs as living, integrated components of the research lifecycle. That vision continues today, as we are helping launch a new initiative at RDA to update a common API standard for DMP service providers. This effort will help ensure our systems can connect more seamlessly and serve the broader research ecosystem more effectively. This post gives some context on why this new effort is needed, what we’ve done so far for it, and what we have coming next.
DMP Tool implementation of the RDA common standard
The DMP Tool team were early advocates of maDMPs and saw the potential value of capturing structured information during the creation of a DMP. The goal is to use as many persistent identifiers (PIDs) as possible to help facilitate integrations with external systems. To gather this data, we introduced new fields into the DMP Tool to capture detailed information about project contributors (ORCIDs, RORs, and CRediT roles) as well as what repositories (re3data), metadata standards (RDA metadata standards) and licenses (SPDX) would be used when creating a project’s research outputs. These new data points are captured alongside the traditional DMP narrative. We also started allowing researchers to publish their DMPs. This process generates a DMP ID, a DOI customized to capture and deliver DMP-focused metadata. This approach allows the DMP to be discoverable in knowledge graphs like DataCite Commons. Once the DOI is registered, the DMP Tool provides a landing page for the DOI.

One of the main points of collecting all of this structured metadata is to facilitate integrations with other systems. To make that possible, we introduced a new version of the API that outputs the DMP metadata in the common standard developed with RDA. Our first integration was with the RSpace electronic lab notebook system. When a researcher is working in RSpace, they are able to connect RSpace with the DMP Tool to fetch their DMPs in PDF format and store the document alongside their other research outputs. Once connected, RSpace is able to send the DMP Tool the DOIs of any research outputs that the researcher deposits in repositories like Dataverse or Zenodo. These DOIs are then available as part of the DMPs structured metadata.
Moving the Standard Forward
The original RDA DMP common standard was released 3 years ago. Since that time, systems like the DMP Tool have found areas where we need to deviate from the base standard. This is a normal process when any standard is developed and first put into use. We have discovered key fields that should be added to the standard (e.g., contributor affiliation information) and areas that don’t really make sense to capture within the DMP itself (e.g., the PID systems a particular repository supports).
Other DMP systems have also been implementing the common standard and making it available via API calls, but this was done without conformity as to how an external system can access those APIs. This results in systems like RSpace needing to develop and maintain separate integrations for each tool. Over time, this extra work leads to fewer integrations between systems, making each more siloed.
RDA is made up of Interest Groups and Working Groups where members across the world join together to work on a common topic, making guidelines, best practices, tools, standards, and other resources for the wider community. To tackle this use case and address shared issues, our RDA group decided to release a new version of the common standard, v1.2, and forming a new working group to develop API standards that each tool should support. Members of the DMP community gathered together at the end of March to discuss both topics. The DMP systems represented at the meeting included Argos, DAMAP, Data Stewardship Wizard, DMPonline, DMP OPIDoR, DMP Tool, DMPTuuli, and ROHub.
Our DMP Tool team attended the meeting to make sure that the needs of our funders, researchers and institutions were properly represented. The meeting was split into two parts:
- Common Standard revisions: In the morning, the group reviewed issues and feature requests submitted to the DMP Common Standard GitHub repository over the past three years. These were synthesized into major themes for discussion, resulting in a set of proposed non-breaking changes for a v1.2 release. More complex revisions were deferred for a future v2. Those interested can explore the open issues here.
- Drafting the API specification: In the afternoon, the group reviewed user stories from current and planned integrations to identify common needs. This discussion led to the initial outline of a shared set of API endpoints that each DMP service should support. Work on refining this draft will continue in the coming months.

Next steps
The original common metadata standard working group plans to incorporate the proposed non-breaking changes this summer as release v1.2. We have also committed to keep the conversation going about future enhancements as we work towards v2.
Meanwhile, the new RDA working group also hopes to release an official API specification this summer. The individual tools would then be tasked with ensuring that their systems support the new API endpoints. For our part, the DMP Tool will ensure that our new website supports this API standard when it launches, as well as additional endpoints specific to our application. The goal is that integrator services like RSpace will then be able to connect more easily with any DMP service, making connections across the research system more robust.
Anyone can review the new DMP common API for maDMP working group proposed work statement. We would value your input, and if you’re interested in joining the group and contributing to the API specification, you can join RDA (its free!) and join our Working Group.
UC3 New Year Series: Looking Ahead through 2025 for the DMP Tool
At UC3, we’re dedicated to advancing the fields of digital curation, digital preservation, and open data practices. Over the years, we’ve built and supported a range of services and actively led and collaborated on initiatives to open scholarship. With this in mind, we’re kicking off a new series of blog posts to highlight our core areas of work and where we’re heading in 2025.
We’re gearing up for a big year over at the DMP Tool! Thousands of researchers and universities across the world use the DMP Tool to create data management plans (DMPs) and keep up with funder requirements and best practices. As we kick off 2025, we wanted to share some of our major focus areas to improve the application and introduce powerful new capabilities. We always want to be responsive to evolving community needs and policies, so these plans could change if needed.
The DMP Tool in 2025
Our primary goal for the year is to launch the rebuild of the DMP Tool application. You can read more detail about this work in this blog post, but it will include the current functionality of the tool plus much more, still in a free, easy to use website. The plan is still to release this by the end of 2025, likely in the later months (no exact date yet). We’re making good progress towards a usable prototype of core functionality, like creating an account and making a template with basic question types.
Another common request is to offer more functionality within our API. For example, people can already read registered DMPs through the API, but many librarians want to be able to access draft DMPs to integrate a feedback flow on their own university systems. As part of our rebuild, we are moving to a system that is going to use the same API on the website as the one available to external partners (GraphQL for those interested). This will allow almost any functionality on the website to be available through the API. This should be released at the same time as the new tool, with documentation and training to come. Get your integration ideas ready!
Finally, we are continuing to work on our related works matching, tracking down published outputs and connecting them to a registered DMP. This is part of an overall effort to make DMPs more valuable throughout the lifecycle of a project, not just at the grant submission stage, and to reduce burden on researchers, librarians, and funders to find related works. It’s too early to tell when this will be released publicly on the website, but likely will come some time after the rebuild launch.
AI Exploration
While most of our focus will be on the above projects, we are in the early stages of exploring topics for future development of the DMP Tool. One big area is in the use of generative AI to assist in reviewing or writing data management plans. We’ve heard interest from both researchers and librarians in using AI to help construct plans. People sometimes write their DMP the night before a grant is due and request feedback without enough time for librarians to provide it. AI could help review these plans, if trained on relevant policy, to give immediate feedback when there’s not enough time for human review.
We’re also interested in exploring the possibility of an AI assistant to help write a DMP. We know many people are more comfortable answering a series of multiple choice questions than they are in crafting a narrative, and it’s possible we could help turn that structured data into the narrative format that funders require, making it easier for researchers to write a plan and keeping the structured data for machine actionability. Another option is an AI chatbot within the tool that can help provide our best practice guidance in a more interactive format. It will be important for us to balance taking some of the writing burden off of researchers while making sure that they are still the one responsible for the content within it.
These ideas are in early phases – it’s something we’ll be exploring but not releasing this year – however we’re excited about their potential to make DMPs easier to write.
Community Engagement
While it may seem we’ll be heads down working on these big projects, we want to make sure we’re communicating and participating in the wider community more than ever. As we get towards a workable prototype of the new tool, we’ll be running more user research sessions. The initial sessions, reviewed here, offered a lot of valuable insight that shaped the current designs, and we know once people get their hands on the new tool they’ll have more feedback. If you haven’t already, sign up here to be on the list for future invites.
We also want to be more transparent with the community about our operations and goals. We’ve started putting together documents within our team about our Mission and Vision for the DMP Tool, which we’ll be sharing with everyone shortly. Over 2025, we want to continue to work on artifacts like those we can share regularly so that you all know what our priorities are. One goal is to create a living will, recommended by the Principles of Open Scholarly Infrastructure, outlining how we’d handle the potential winddown of CDL managing the DMP Tool. This is a sensitive area because we have no plans to wind down the tool, and don’t want to give the impression that we will! But it’s important for trust and transparency for us to have a plan in place if things change, as we know people care about the tool and their data within it.
Finally, we’ll be wrapping up our pilot project with ARL this year, where we had 10 institutions pilot implementation of machine-actionable DMPs at their university. We’ve seen prototypes and mockups for integrations related to resource allocation, interdepartmental communication, security policies, AI-review, and so much more. We’ve brought on Clare Dean to help us create resources and toolkits, disseminate the findings, and host a series of webinars about what we’ve learned to help others implement at their own universities. We’ll be presenting talks on the DMP Tool at IDCC25 in February, RDAP in March, and we plan to submit for other conferences throughout the year, including IDW/RDA, to share what we’ve learned with others. We hope to continue working with DMP-related groups in RDA to ensure our work is compatible with others in the space, and we’re following best practices for API development.
We hope you’re as excited for these projects as we are! We’re a small team but we work with many amazing partners that help us achieve ambitious goals. Keep an eye on this space for more to come.