(index page)
Persistent Identifier Services at CDL: A Rich Tapestry
EZID is one strand in a larger tapestry of persistent identifier activity at CDL. These activities, at their core, are focused on how and where persistent identifiers can help enrich and connect the scholarly outputs and cultural heritage materials of the University of California system. Persistent identifiers in this sense both drive and support CDL’s underlying mission to “provide[s] transformative digital library services, grounded in campus partnerships and extended through external collaborations, that amplify the impact of the libraries, scholarship, and resources of the University of California.”
The past year was a transitional one for EZID in particular and for CDL’s identifier services portfolio in general. In the first half of 2019, we completed a multi-year process to rescope EZID’s DOI services to focus exclusively on UC users. We worked to support non-UC users of our DOI services in setting up direct memberships with other providers through memberships with Crossref and DataCite. We also welcomed Rushiraj Nenuji to the development team as we said farewell to EZID’s long-time developer and original architect Greg Janée.
Last year, in the midst of these transitions, we posed the following question:
Rather than thinking about EZID solely as a tool or a service, we want to situate it instead as one layer of a deep and broad persistent identifier portfolio at CDL. EZID is a great tool for creating and managing DOIs and ARKs—what else could it do? And how might it also support infrastructure, training, and outreach for a more networked and interoperable scholarly communication ecosystem through the use and coordination of persistent identifiers?
Now, as we kick off the new year, we wanted to provide a brief update on what this persistent identifier services portfolio looks like, and how it will continue to evolve in the months ahead.
EZID remains involved in the day-to-day business of supporting DOI and ARK services for UC campuses as well as ARK services for non-UC EZID members. EZID development work is currently focused on strengthening and upgrading the application for long-term robustness and stability, and reconfiguring the platform to minimize dependencies on external systems. Future development work in the coming months will be geared toward optimizing the EZID user interface and adding more support for different metadata schemas.
From the portfolio perspective, we are working on a number of initiatives to encourage and enable the adoption and use of persistent identifiers across the UCs and beyond. A few examples:
We work closely with CDL’s eScholarship Publishing team to help UC journals obtain Crossref DOIs. An integration between eScholarship and EZID assigns DOIs automatically to eScholarship journal articles and sends the metadata to Crossref. These articles are then available to indexes, libraries, and other third parties, enhancing journals’ exposure and increasing the discoverability of their Open Access content. This service supports about 20 journals and our teams will expand to more publications in the year ahead. Two related efforts concern greater adoption of ARK identifiers for special collections objects (UCSF’s Industry Documents Library is one recent project), and DataCite DOIs for UC data repositories.
Organization identifiers are growing in visibility across the scholarly infrastructure landscape with the launch of the Research Organization Registry (ROR), of which CDL is a founding partner. The ROR registry now includes unique IDs for approximately 97,000 organizations, and these IDs are being supported in both DataCite and Crossref metadata. A number of platforms are integrating or looking to integrate ROR into their systems wherever affiliations are collected. The new Dryad platform was the first to pilot this type of ROR integration, and Dryad now has clean and consistent affiliation data for all of its datasets. With additional integrations expected in the new year, it will become increasingly easier for libraries and research administrators to track and analyze their institutions’ scholarly outputs.
Engaging with the broader PID community is another important aspect of our ongoing work. CDL is a member of the ORCID US Community, joining other institutions around the country in championing adoption and use of ORCID identifiers by UC researchers. We are also a founding sponsor of PIDapalooza, the festival of persistent identifiers now approaching its fourth year. We are collaborating within and beyond the UC in persistent identifier training and outreach, including providing guidance on identifiers for UC librarians, and organizing global workshops for stakeholders and practitioners.
All of these efforts showcase how persistent identifier services capture the spirit of the CDL’s vision as a “catalyst for deeply collaborative solutions providing a rich, intuitive and seamless environment for publishing, sharing and preserving our scholars’ increasingly diverse outputs.”
We are looking forward to the year ahead! As always, get in touch with your ideas and questions.
Keep on ROR-ing: A Research Organization Registry Update
The Research Organization Registry (ROR) has had a big year! As CDL is a key partner in the ROR initiative, we are posting some updates here about what has been happening with ROR and where we’re going next.
The first prototype of the ROR registry launched in January and now includes unique IDs and metadata records for nearly 100,000 organizations. The registry’s launch marked the culmination of several years of planning and collaboration by numerous organizations and stakeholders from across the scholarly communications landscape to establish a guiding vision and a core set of requirements for open infrastructure for research organization IDs and metadata.
ROR emerged to fill a crucial gap in scholarly infrastructure: while we already had an open network of identifiers for research outputs (DOIs for publications and data) and research contributors (ORCID IDs), open identifiers for research organizations were a missing piece. With ROR we now have the power and the ability to connect and leverage all of these identifiers to enable better discovery and tracking of research outputs across institutions and funding bodies.
In addition to the registry itself, ROR offers open tools for interacting with ROR data and implementing ROR IDs, including a front-end search interface, an open API, a reconciler that works with OpenRefine to clean up messy lists of affiliations, affiliation matching functionality to connect free-text affiliation strings to ROR IDs, and a public data dump. All of the ROR code is available on Github. As we grow the registry, we will be building curation tools for maintaining ROR records over time, establishing a community curation board, and developing more support for system integrations and for usage of registry data.
ROR IDs can be captured now in systems and platforms where researcher affiliations are collected, and supported in Crossref and DataCite metadata. A number of ROR integrations are active or in progress, spanning data repositories, manuscript tracking systems, grant application systems, institutional repositories, and others. One of these early implementations—a simple affiliation lookup in Dryad’s data publishing platform that collects clean and consistent affiliation data for each dataset submitted—is described in this blog post.
ROR is run as a community collaboration and led by academic and nonprofit organizations with deep expertise in scholarly communication and open infrastructure initiatives. All of ROR’s work so far has been completed through in-kind donations from its steering organizations. We also have supporters and advisors from across industries and around the world.
In the coming years, we want to further develop ROR to enable greater adoption and downstream uses. Our organizations are committed to ROR for the long-term but we can’t move forward without additional community support. We have launched a fundraising campaign in order to be able to scale up our operations, hire dedicated staff, and develop and deliver new features, with a plan to launch a paid service tier in 2022 to recover costs while keeping the registry’s data open and free for all.
The ROR campaign’s first fundraising target is $75,000 by the end of 2019, and we have raised $36,000 so far, bringing us nearly halfway to our year-end goal. We are grateful to the following supporters for getting the campaign off to a strong start:
- Altum
- American Physical Society
- American Psychological Association
- Association for Computing Machinery
- Center for Science and Technology Studies (CWTS), Leiden University
- Curtin University
- Dryad
- eLife
- German National Library of Science and Technology (TIB)
ROR’s growing community of supporters speaks to the importance of building and sustaining open infrastructure for scholarly communications.
Steve Pinchotti, CEO of Altum—which has integrated ROR IDs into 26,000 institution profiles in its ProposalCentral grants platform—stated:
“ROR is a critical component of a connected research data landscape. As a software company focused on the advancement of research, Altum recognizes our responsibility to financially support and sustain the key research infrastructure initiatives like ORCID and ROR that enable open science and open global identifiers for research outputs, research contributors, and research institutions.”
Melissa Harrison, Head of Production Operations at eLife, adds:
“The distribution of high-quality metadata using various persistent identifiers is a great tool for advancing connections and the interlinking of scholarly content with other aspects of the ecosystem. We are delighted to support this community-led initiative for an open persistent identifier for research organizations to complement those we at eLife already use for content, peer review, data, people and funding.”
As we approach the end of the year, we are calling on our community to help ensure we will reach our goal. Contributions in any amount are welcome, and will go directly to support the registry’s growth and development. To start your contribution, email donate@ror.org to make a pledge and request an invoice. There are other ways to contribute as well—by spreading the word about the campaign, by implementing and adopting ROR IDs, and by telling others why open scholarly communications infrastructure matters to you.
Thank you for supporting ROR!
ROR-ing Together: Implementing Organization IDs in Dryad
Co-authored by Maria Gould and Daniella Lowenberg and cross-posted from the ROR blog
How many datasets have been published in Dryad from researchers at the University of California? This question is surprisingly complicated. A short answer might be, we don’t know! A better answer could be, coming soon – stay tuned!
And a more complete and detailed answer might go something like this:
It’s not easy to determine how many datasets in Dryad are affiliated with the University of California – or any other institution, for that matter. This is the result of two main factors: (1) Dryad historically did not collect affiliation information from authors submitting datasets; and (2) even if Dryad had collected this information, it likely would have done so in a free-text field that allowed authors to write their affiliation in any number of ways (think “UC Berkeley,” “University of California-Berkeley,” or “Berkeley,” for example). Why? Because until recently, the scholarly research and publishing community did not have an easy and open option to rely on a standard set of affiliation names and related IDs to identify and disambiguate institutions.
This changed a few months ago with the launch of ROR – the Research Organization Registry. ROR is a community-led project to develop an open, sustainable, usable, and unique identifier for every research organization in the world. The ROR MVR (minimum viable registry) launched in January 2019 and began assigning unique ROR IDs to more than 91,000 organizations.
At its core, ROR is focused on filling a very specific and crucially important gap in scholarly research and publishing infrastructure: information about the organizations affiliated with researchers and research outputs. The rise of DOIs to identify datasets and publications and ORCID IDs to identify researchers and contributors has facilitated more efficient discovery and tracking of research outputs. But without being able to identify where these outputs and authors are affiliated, this discovery and tracking can only go so far. At best, an immense amount of additional and manual work is involved in extracting this information to fill the gap. At worst? The gap never gets filled in. With ROR IDs, the idea is that both of these scenarios no longer happen. ROR is intended for use by the research community, for the purposes of increasing the use of organization identifiers in the community and enabling connections between organization records in various systems.
ROR and Dryad joined forces this spring to tackle two different yet related challenges. Following the launch of the MVR, ROR was interested in finding a partner to pilot a simple yet effective implementation of the ROR API. Dryad was interested in implementing a solution to the problem of missing affiliation data. As a longstanding community partner in data publishing and open infrastructure projects, the Dryad team was eager to be an early adopter of ROR and blaze the trail toward wider implementation and collection of ROR IDs across multiple systems and platforms.
Dryad’s developers working on the new Dryad platform (launching later this summer) quickly got to work creating an affiliation field in the dataset submission form that calls the ROR API. When an author starts typing an affiliation, the field lookup searches for a matching name in ROR and shows the author a dropdown list of possible matches to choose from.
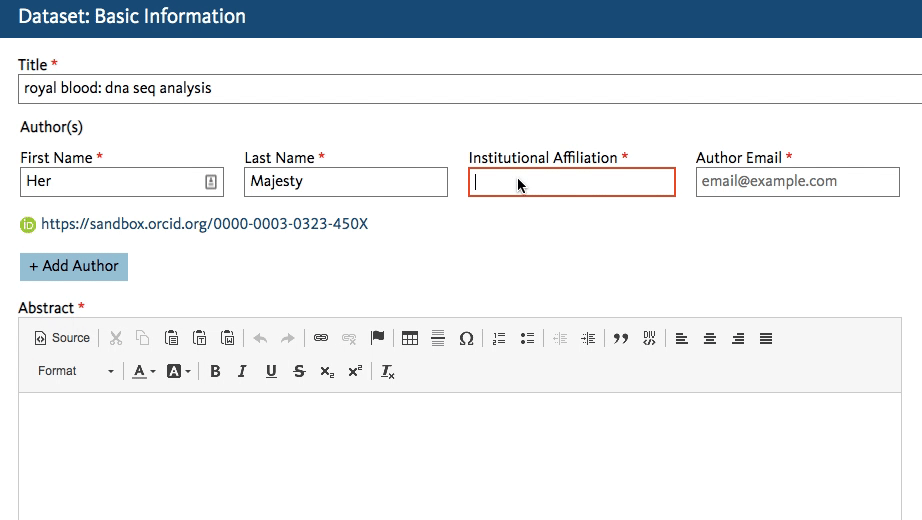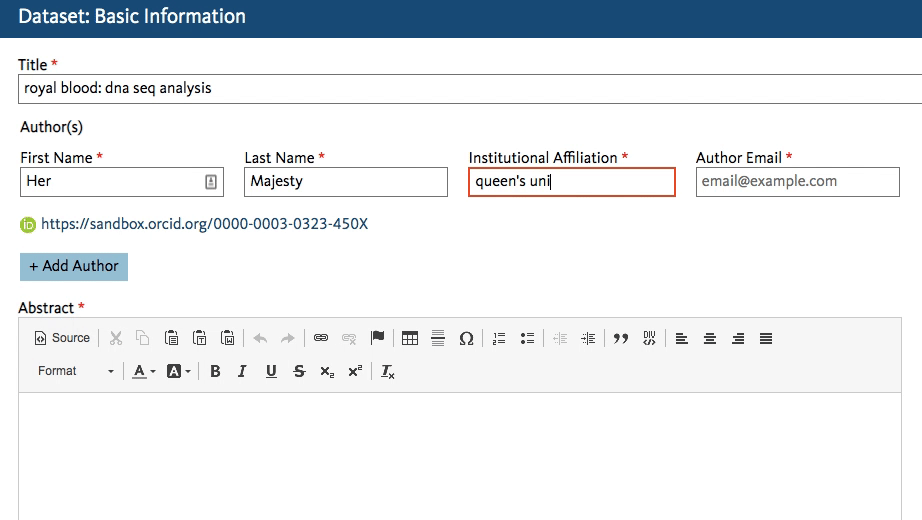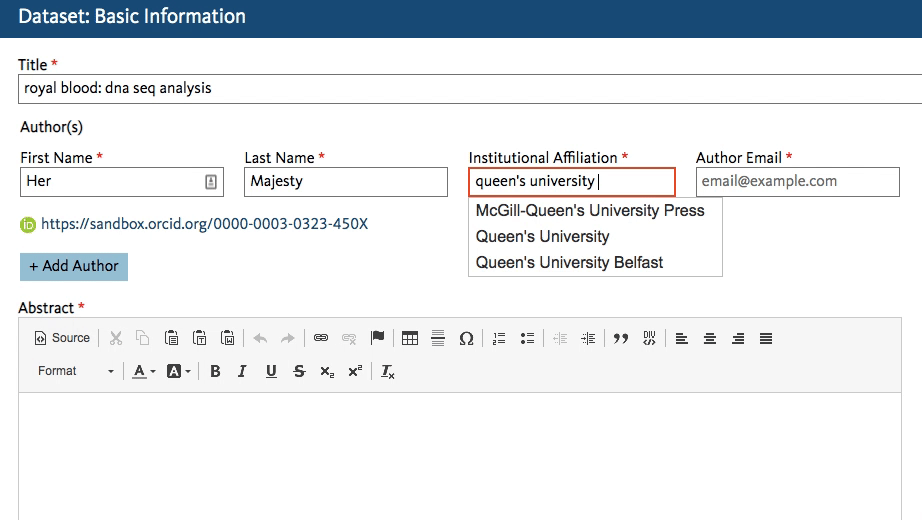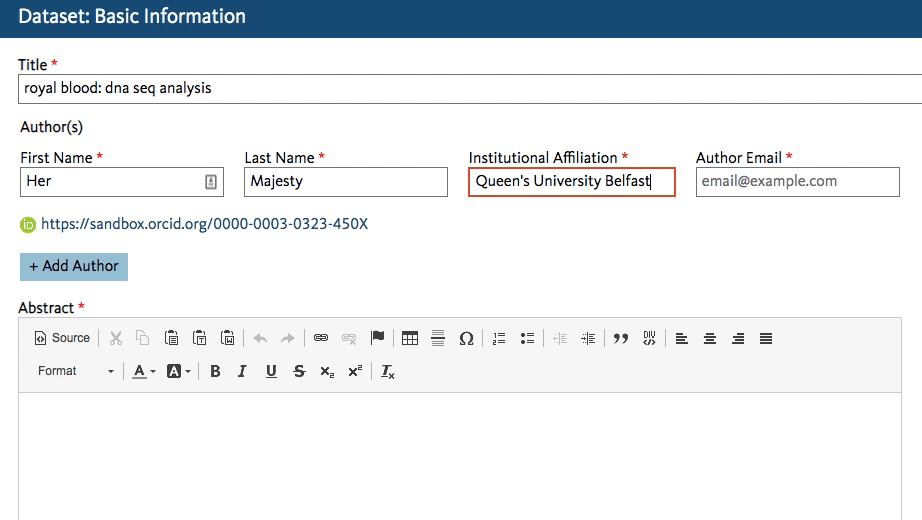
This will work regardless of whether the author starts entering a known abbreviation or the full name of the organization, as shown below.
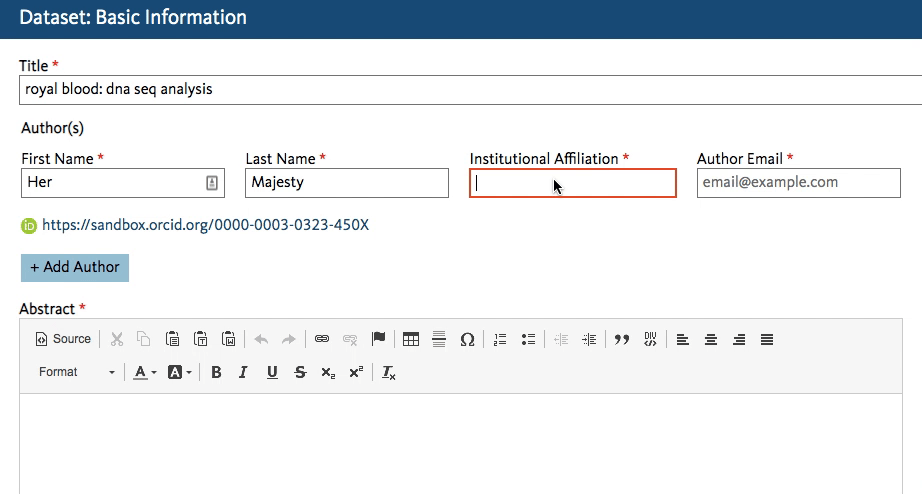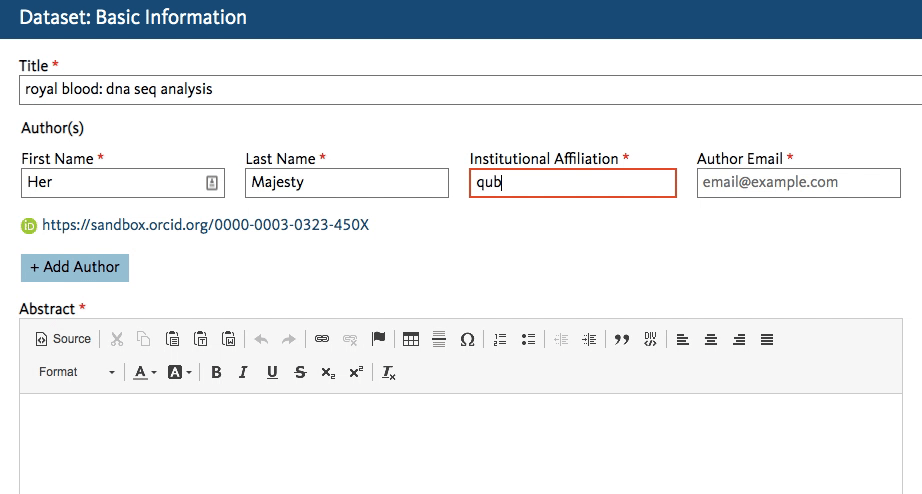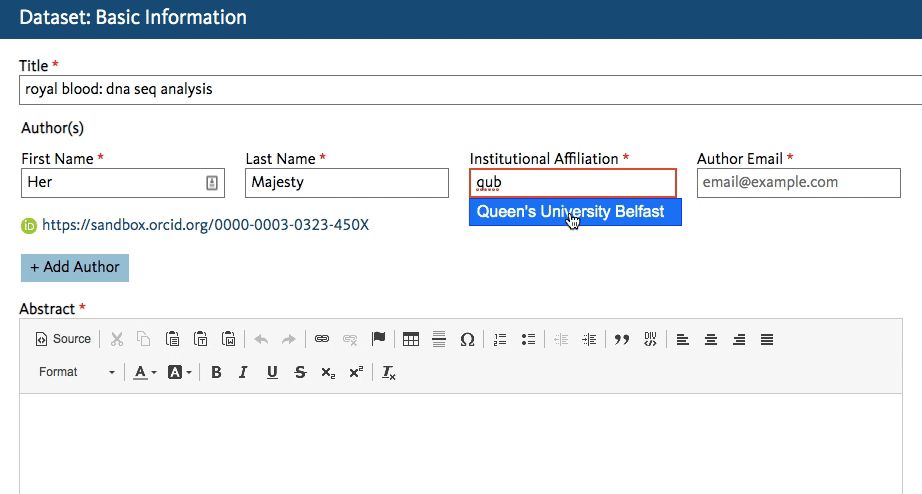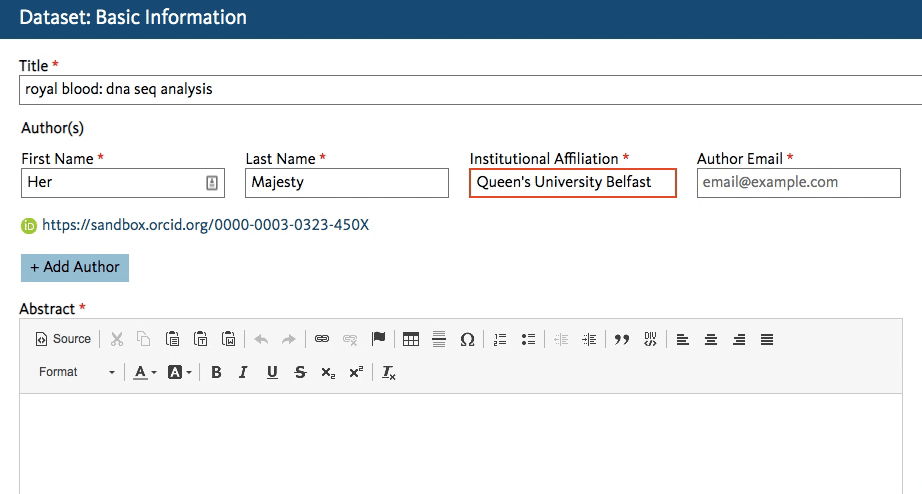
The author chooses the match and proceeds with the submission. The ROR ID is stored in the database – the author doesn’t even have to know it exists!
At this point you are probably curious about a few things: Can users override the matching and type whatever they want? What happens if a user’s affiliation is not found in the lookup? And how easy is it to implement this super-cool functionality in my platform?
We’ll address these questions in order:
Can users override the matching? Yes, the system will not prevent them from typing in an affiliation instead of choosing from the list. This is necessary to ensure a smooth submission process and also to allow for rare cases in which the user’s affiliation is not easily found in the lookup. In both of these situations, this is where Dryad’s curation workflow comes into play. A team of curators who go through each data submission will note if the affiliation is not a ROR ID, alter it if there is an existing one, or flag it for the ROR team to investigate and add to their corpus.
Now, how easy is it to implement this functionality in other systems? You can do it right now! Dryad’s code base is open-source and the team is happy to walk you through the implementation of ROR look up and autofill. To discuss the implementation you can get in touch here.
DataCite’s DOI registration system, known as Fabrica, already includes a similar lookup so this is a useful implementation to reference as an example as well.
With the ROR affiliation lookup implemented in Dryad, the future looks bright when it comes to the challenge of identifying research outputs by institution, as every new dataset submitted to Dryad will be associated with a ROR ID. But what about the datasets that are already in Dryad? As you’ll recall from the beginning of our story, affiliation details were not previously collected in Dryad at the time these datasets were submitted. This gap represents the work of approximately 90,000 researchers over the past ten years. The Dryad team wanted to ensure that these datasets had ROR IDs as well, so they teamed up with Ted Habermann (Metadata Game Changers) to identify those missing affiliations. By pulling from open APIs (Crossref, PLOS, Unpaywall, etc) and manually looking up affiliations from related articles, Ted is transforming a corpus of raw affiliations into standardized ROR IDs. Though it is a cumbersome project, this will ultimately allow for Dryad to have an entire database of ROR IDs for all past and future authors publishing their data.
The Dryad-ROR collaboration shows the promise and power of implementing organization IDs in publishing platforms to enable better tracking and discovery of research outputs by institution. We’re excited about this use of ROR and eager to see other platform providers pursue similar implementations in the coming months. Feel free to get in touch with your ideas and questions!
Hear Us ROR! Announcing Our First Prototype and Next Steps
What has hundreds of heads, 91,000 affiliations, and roars like a lion? If you guessed the Research Organization Registry community, you’d be absolutely right!
Last month was a big and busy one for the ROR project team: we released a working API and search interface for the registry, we held our first ROR community meeting, and we showcased the initial prototypes at PIDapalooza in Dublin.
We’re energized by the positive reception and response we’ve received and we wanted to take a moment to share information with the community. Here are the links to our latest work, a recap of everything that happened in Dublin, some of the next steps for the project, and how the community can continue to be involved.
🎉 Ta da! The first ROR prototype
The Research Organization Registry (ROR) is finally here! We’re thrilled to officially announce the launch of our ROR MVR (minimum viable registry). The MVR consists of the following components, which are ready for anyone to use right now.
- ROR IDs: Starting with seed data from GRID, ROR has begun assigning unique identifiers to approximately 91,000 organizations in its registry. ROR IDs include a random, unique, and opaque 9-character string and are expressed as URLs that resolve to the organization’s record. For instance, here is the ROR ID for California Digital Library: https://ror.org/03yrm5c26
- Search: We also built a search interface to look up organizations in the registry: https://ror.org/search.

- ROR records: ROR IDs are stored with additional metadata about the organization, such as alternate names/abbreviations, external URLs (e.g., an organization’s official website), and other identifiers, such as Wikidata, ISNI, and the Open Funder Registry. This metadata will allow ROR to be interoperable with other identifiers and across different systems. The current schema is based on GRID’s dataset and we plan to incorporate other metadata fields over time and according to community needs.

- API: The ROR API is now public. You can access the JSON files at https://api.ror.org/organizations.
- OpenRefine reconciler: We’ve released an OpenRefine reconciler that can map your internal identifiers to ROR identifiers: https://github.com/ror-community/ror-reconciler.
- Documentation: We have begun storing documentation on Github and will be adding more as we go along. Please feel free to follow and contribute: https://github.com/ror-community.
Community meeting recap
On January 22, 60+ representatives from across the research and publishing community gathered in Dublin to see what the ROR project team has been up to, demo the first prototypes in action, and discuss where we want to go next – and, of course, to practice ROR-ing together.

In the second half of the meeting, attendees split into discussion groups to identify specific aspirations for ROR and brainstorm concrete actions needed to achieve these goals, focusing on the main use case of exposing and capturing all research outputs of a given institution. The proposed ideas covered a spectrum of possibilities for ROR, highlighting the following themes:
ROR as seamlessly-integrated and sometimes invisible infrastructure
- Integration between and within existing systems (and in new ones!)
- Auto-detection of ROR IDs for example in manuscript tracking and funding application platforms
- As such, researchers don’t ever have to be responsible for knowing what a ROR is and using it appropriately – the systems they use will do this for them.
ROR as a critical piece of funder workflows and infrastructure
- Demonstrate to funders how ROR can help them analyze impact of research they fund
- Conduct outreach with key international funders, especially those interested in open infrastructure
- Make funders aware of ROR and encourage them to adopt and mandate use of ROR IDs – involve funders at the beginning to collaborate on technology
- Integrate ROR with existing systems and identifiers already in use by funders and other stakeholders
ROR as a trusted registry, collaborative partner, and responsible steward
- Culturally sensitive, inclusive, and respectful of what countries are already doing with regard to organizational identifiers, partnering with national bodies working on this and mapping ROR IDs to locally used identifiers.
- Involve the institutions listed in the registry early on as well as CRIS systems
- Interoperability with existing communities and governance bodies
- Workflows to support trust and responsible management of organizational metadata, with policies and procedures for long-term curation and maintenance of records
What we’re hearing
Now that the ROR MVR is here, we’re hearing some really good questions about the data we’re capturing, how it can be used, and how we’ll be maintaining the registry going forward. We wanted to take a moment to respond to some of these questions.
What is the criteria for being listed in ROR? What is a “research organization”?
We define the notion of “research organization” quite broadly as any organization that conducts, produces, manages, or touches research. This is in line with ROR’s stated scope, which is to address the affiliation use case and be able to identify which organizations are associated with which research outputs. We use “affiliation” to describe any formal relationship between a researcher and an organization associated with researchers, including but not limited to their employer, educator, funder, or scholarly society.
Will ROR map organizational hierarchies?
No – ROR is focused on being a top-level registry of organizations so we can address the fundamental affiliation use case, and provide a critical source of metadata that can interoperate with other institutional identifiers.
ROR IDs are cool – what can I do with them?
Now that we have built our MVR, we will be working to incorporate ROR IDs into relevant pieces of the scholarly communication infrastructure. If you are a publisher, funder, metadata provider, research office, or anyone else interested in capturing affiliations, please get in touch with us to discuss how we might coordinate. If you are a developer, you are welcome to start playing around with the API: https://api.ror.org/organizations.
There’s an error in my organization’s ROR record — can you fix it?
For the time being, please email info@ror.org to request an update to an existing record in ROR or request that a new record be added. We will formalize our data management policies and procedures in the next stage of the project.
What is ROR’s relationship to other organizational identifiers?
For ROR to be useful, it needs to augment the current offerings in a way that is open, trusted, complementary, and collaborative, and not intentionally competitive. We are committed to providing a service that the community finds helpful and not duplicative, and enables as many connections as possible between organization records across systems.
I have my own dataset of institutional affiliations — can I give it to ROR?
We are always happy to hear about other efforts to capture affiliation data. Please get in touch with us to discuss how we might coordinate.
Can ROR support multiple languages and character sets?
GRID already supports multiple languages and character sets, so by extension ROR will have this enabled as well. Here is one example: https://ror.org/01k4yrm29.
How will ROR handle curation, i.e., updating records if an organization changes its name or ceases to exist?
The curation and long-term management of records will be a cornerstone of our efforts in 2019 and we hope to release a working set of policies and procedures soon.
What’s next for ROR
Now that we have our MVR, what happens next for ROR? We’re eager to sustain the momentum from January’s stakeholder meeting at the same time we know there are some longer-term plans to put in place, and so we’re looking at both some immediate tasks as well as bigger-picture questions.
Product development
We have a few to-do items on our list following the launch of the MVR to keep everything running smoothly while we develop a comprehensive long-term product roadmap.
- Rewrite some of the code for both the API and the OpenRefine reconciler
- Address a few bugs in our repos
- Provide guidance for troubleshooting issues
- Communicate our processes for users to request changes, report bugs, and suggest features
As a reminder, you can access the existing code in Github: https://github.com/ror-community
Policy development
We’ve been emphasizing here and in community conversations that our primary focus now turns to formulating policies and procedures to ensure the successful management of ROR data over the long term. This is something we can’t (and shouldn’t) do on our own — we want to work with community stakeholders to develop the right solutions and establish the right frameworks. We understand the urgency of firming up these policies, but we are also aware that something this important can take time to complete and is not something to rush into lightly.
Community development
To help guide the next stages of the project, we are putting out an open call for participation in the ROR community advisory group. Advisory group members will be involved in giving input on data management, testing out new features, giving feedback on the product roadmap, and discussing ideas for events and outreach. We plan to convene this advisory group through bimonthly calls and asynchronous communication channels through the end of the year. We hope you will consider joining us! Please email info@ror.org if you are interested.
For those who want to stay informed about the project but not necessarily be part of the advisory group, you have other options!
- Sign up for our mailing list (via the footer at ror.org)
- Join our community on Slack (www.tinyurl.com/ror-community),
- Follow us on Twitter (@ResearchOrgs).
You can also always drop us a line at info@ror.org, and let us know if you’d ever like to set up a meeting or conference call to talk about the project in more detail.
Final thoughts
Community engagement has been vital to ROR’s beginnings and will likewise be critically important for the next steps that we take. As both a registry of identifiers and a community of stakeholders involved in building open scholarly infrastructure, ROR depends on guidance and involvement at multiple levels. Thank you for being part of the journey thus far, and for joining us on the road that lies ahead. 🦁
This has been cross-posted from the ROR blog