(index page)
Introducing FAIR Station’s Product Manager

Hello everyone! My name is Danny Brooke, and I’m excited to join UC3 as Product Manager for FAIR Station, a role hosted through Code for Science & Society. FAIR Station is a Moore Foundation-funded initiative that’s building open-source, interoperable infrastructure for field stations and marine laboratories. The project reimagines RAMS (a field station reservation platform) as a strategic entry point into the research lifecycle, connecting fieldwork to the samples, datasets, and publications that result from it.
I’ve always felt most at home building tools for researchers to work with and share data. I previously worked on The Dataverse Project at Harvard’s Institute for Quantitative Social Science (IQSS), where I had the opportunity to help build open-source data repository software alongside a large community of researchers, librarians, and developers from around the world. Since leaving Harvard, I’ve continued working at the intersection of large-scale data, research workflows, and platform development. This has included building data infrastructure supporting one of the world’s largest canine health and genetics datasets at Embark Veterinary and leading product and consulting work focused on implementing data pipelines and data collection tools that translate complex operational environments into reliable and useful infrastructure.
I’ve missed the opportunity to build products for researchers to connect and share data. I’m happy to be back.
Over the coming months, I’ll be spending time learning from field station and marine laboratory communities, understanding researcher workflows, growing a team, and helping shape the product direction for FAIR Station. I look forward to meeting many of you. Please feel free to connect with me on LinkedIn or at danny.brooke@ucop.edu.
Reflections on Data Stewardship: Farewell to CDL
After three years at my role at the UC3, earlier this year, I left to return to the Scripps Institution of Oceanography as a Visiting Scholar, where I am now focusing on projects focused on climate data preservation. While the move represents a return to my institutional home of more than three decades, my time at CDL and UCOP profoundly shaped how I think about the future of data stewardship and the infrastructure needed to support it.
Bringing research data infrastructure
Before joining UC3, I spent over 30 years at Scripps working in ocean and climate data stewardship. Climate science has long excelled at producing observations that are essential to understanding our planet. But one of the lessons that became clearer during my time at UC3 is that the infrastructure that ensures those data remain accessible, reusable, and preserved over time is just as important.
At UC3, I had the opportunity to work alongside colleagues building exactly that kind of infrastructure. As Senior Product Manager for Data Publishing and Research Data Specialist, I worked across projects focused on data publishing, repository ecosystems, and strengthening community skills in data stewardship.
Whether through collaborations around generalist repositories, work connected to the NIH Generalist Repository Ecosystem Initiative (GREI), or training initiatives such as the RDA School for Research Data Science, or the IMLS-funded Carpentries 2.0 project, I saw firsthand how UC3 approaches research data as an ecosystem. The experience reinforced a simple but powerful insight: data that are truly FAIR rarely need rescuing.
The growing urgency of climate data preservation
That insight has become increasingly important as climate researchers confront the challenge of preserving and mobilizing critical environmental data. During my time at CDL, I helped co-found the Climate/Ocean Data Action Network (CO-DAN), a grassroots coalition of data professionals, scientists, librarians, and technologists working together to coordinate climate data preservation efforts. What began as emergency “data rescue” work quickly revealed deeper structural challenges in how climate data are managed and preserved.
The work happening at UC3 helped illuminate what a more sustainable approach could look like. Professional data stewardship infrastructure, the kind UC3 exemplifies, provides the standards, tools, and community coordination needed to ensure that important data remain available for future research.
Returning to Scripps with new tools and perspectives
Now back at Scripps as a Visiting Scholar, I am working with the Sandin Lab and the Scripps Polar Center on data related to ice sheet and ocean interactions, while continuing to collaborate with colleagues across the climate and data stewardship communities.
My time at UC3 provided something that climate science urgently needs: deeper exposure to the professional infrastructure that supports long-term data stewardship. That perspective is now informing the work I’m doing at Scripps and in the broader climate data community. In addition to my work at Scripps, I continue to contribute to several organizations focused on climate data, research infrastructure, and equity in science, including the New York Climate Exchange, the Keeling Curve Foundation, the Southern Ocean Observing System, Earth Science Information Partners (ESIP), Scientific Committee on Antarctic Research (SCAR), and the American Geophysical Union.
Gratitude
Looking back, my time at UCOP and CDL was invaluable. The colleagues I worked with, the UC-wide perspective I gained, and the professional infrastructure expertise I built have prepared me for what comes next in ways I couldn’t have anticipated. I look forward to continued collaboration with UC colleagues as we work together to build more resilient data infrastructure. In many ways, this transition feels less like a goodbye and more like a continuation of a conversation. Although I’ve returned to Scripps, I don’t see this as the end of my connection to CDL and UCOP. Many of the challenges facing climate science and research data infrastructure are shared challenges, and I know our paths will continue to cross.
Our Path to FAIR Station
At UC3, our work focuses on how research activities, outputs, and systems connect across the lifecycle, from planning and data collection through to publication and reuse. We approach these challenges from a research infrastructure and information management perspective, which naturally extends upstream to where research begins, including field stations and other place-based environments. As we embark on the FAIR Station project, we wanted to reflect on some of the many projects and work that got us to this point.
Early foundations
UC3 was founded as CDL’s digital curation program to focus on supporting the full research lifecycle. For more than 15 years, our work has centered on enabling connections from planning and data collection. One of our most formative collaborations was with the DataONE community. That vision was ambitious: to support discovery, access, and reuse of environmental data across a distributed landscape, grounded in the realities of field-based, place-dependent research.
DataONE’s emphasis on lifecycle coordination and distributed data collection reinforced the importance of capturing context at the point of origin. These ideas, grounded in foundational work by UC3 and supported through NSF investment, continue to inform our work. At the same time, UC3’s other collaborations explored various entry points into the research lifecycle.
As a founding member of the DataCite community, we helped lead the adoption of DOIs for research data, strengthening how outputs are identified and connected. The DMPTool supports planning and structuring, while repository services enable publication and citation. In parallel, early work on field station identifiers, including pilots and community presentations, surfaced the importance of treating place as a first-class entity rather than background context.
Engagement with communities such as RDA, ESIP and OBFS further highlighted the challenges of connecting data, samples, and locations across distributed systems. This work established a strong foundation, but also exposed a critical gap: research context is not consistently captured or linked across the lifecycle.
Making infrastructure actionable
Over the past 10 years, a series of funded projects and community initiatives focused on strengthening the connective tissue of the research ecosystem. This included:
- Machine-actionable data management plans (NSF EAGER, 2017)
- Elevating data as a first-class research output (Sloan Foundation, 2017)
- Open data metrics and citation practices through Make Data Count (NSF EAGER, 2014)
- Sustainable model for the Research Organization Registry (ROR) (IMLS, 2020)
- Better research data management through vertical interoperability (NSF Conference, 2024)
During this period, UC3 also contributed to building shared identifier infrastructure, including the Research Organization Registry (ROR) (NSF EAGER, 2020) and broader PID strategy efforts. This work built directly on earlier exploration with the OBFS and NAML on field station identifiers, where efforts to identify place-based environments shaped our thinking about organizational identity, disambiguation, and persistent identifiers. This work established the ability to link research entities, while also making clear that identifiers alone are not sufficient without being embedded into real workflows.
During this same time, UC3 also worked closely with Dryad to evolve it into a platform for experimentation: collaborating on affiliation tracking, linking datasets to software and publications, and early integrations with data management planning workflows. These efforts moved infrastructure into practice, but also highlighted a limitation: much of our work remained downstream. The question of how to integrate these capabilities into place-based research environments remained.
FAIR Island: Infrastructure, Policy, and Practice
Over the years, UC3 has seen increasing alignment across our work in data management planning, persistent identifiers, and research outputs, and recognized an opportunity to bring these together in a place-based context. Through a partnership with UCNRS, and in particular with our frequent collaborators at the Gump South Pacific Research Station, we identified the field station reservation process as a strategic point of engagement where these elements could be introduced earlier in the research lifecycle.
UC3 made the case internally to pursue this work, leading to initial UC investment in what became the FAIR Island project. The core idea was to take the data policies and expectations typically expressed in grant applications and DMPs, and embed them directly into field station workflows. By working to integrate the DMP Tool with the UCNRS Reservation Application Management System (RAMS), we began exploring how policy, identifiers, and metadata could be introduced at the point where researchers request access to field sites.
This work marked the beginning of a deeper collaboration across UCOP, bringing together research infrastructure and operational systems that support day-to-day field station activities. With subsequent NSF support, FAIR Island expanded to include additional partners, including Metadata Game Changers and the Tetiaroa Society, allowing us to test more complete, end-to-end workflows across planning, data collection, and downstream integration.
Our work on FAIR Island demonstrated the importance of the reservation process. It represents a moment where researchers are already providing structured information, making it a natural and effective place to introduce data policies, identifiers, and expectations that can carry forward through the rest of the research lifecycle. This began a shift from connecting data after the fact to embedding those connections where research begins.
FAIR Samples and vertical interoperability
Building on this foundation, our recent projects have expanded into data collection workflows and cross-system integration. The FAIR Samples project (NSF EAGER, 2024) focuses on improving how physical samples are identified, described, and connected across workflows. A key focus is integrating sample management systems with the broader research ecosystem. This work builds on the concept of vertical interoperability, developed by our partners at RSpace, which focuses on how information moves across layers of the research process, from planning tools and field data collection to lab systems and repositories.
Rather than introducing new systems, the FAIR Samples approach emphasizes connecting existing infrastructure, including IGSNs for samples, tools like FieldMark for structured field data capture, and platforms like RSpace for managing and linking workflows. Together, these integrations demonstrate how coordinated tools can support end-to-end workflows without requiring entirely new systems.
FAIR Station: Bringing it all together
This brings us to FAIR Station. This project is not a new direction, but a continuation of our broader efforts to connect place, samples, and data across the research lifecycle.
Collaboration with UCNRS and work with its RAMS platform has been central to our efforts. What began as an operational system that was not easily extended has, through sustained UC investment, evolved into a platform that is now much better positioned for integration. That shift creates a new phase of opportunity for UC3 and UCNRS to work together on connecting planning, policy, identifiers, and downstream systems in ways that were not previously feasible.
It also opens the door to thinking beyond UC. As RAMS continues to mature, we began exploring how it can be extended and open sourced, creating a foundation that other field stations and research networks can adopt, adapt, and contribute to. The goal is not just to support a single system, but to help enable a broader platform where the global field station community can see themselves and participate. With funding from the Moore Foundation, we can now bring together this work and these partnerships to explore how field station systems can support more connected, interoperable research workflows at scale.
Looking ahead
Across UC3’s projects, there is a consistent way of working: connecting existing efforts, aligning with community practices, and building on infrastructure already in use rather than creating new systems in isolation. All of UC3’s work has only been possible through sustained support from funders and collaboration with communities and partners. That same model is essential for FAIR Station. We will continue to work with field stations, infrastructure providers, and partners like RSpace to extend systems like RAMS and support open, interoperable workflows.
Introducing FAIR Station
Across many areas of research, field stations and marine laboratories (FSMLs) are where science begins. This is where observations are made, samples are collected, and long-term studies take shape. Yet the systems that support this work are often focused on logistics alone: reserving space, coordinating access, and managing operations.
What happens next, how data are described, connected, and ultimately shared, is typically handled elsewhere, and often inconsistently. At UC3, we see this as a missed opportunity. Over the past decade, we have worked on different parts of this challenge. With the FAIR Station project, we are turning our attention upstream to the platform researchers already use to engage with field stations.
A moment that matters
Reserving time at a field station is one of the few universal touchpoints across place-based research. It is a moment where researchers, administrators, and institutional expectations come together. Today, that moment is largely administrative. It could also be where shared practices around data, metadata, and stewardship begin.
The FAIR Station project is built on this idea. Rather than introducing entirely new systems, the FAIR Station approach starts with what already works and asks a different question: what becomes possible if this layer of the research lifecycle is opened up and connected?
Our work will build on the Reservation Application Management System (RAMS), developed by University of California Nature (formerly the UC Natural Reserve System (UCNRS)), and reimagines it as something more than a single-institution system. The goal is to evolve this foundation into an open, extensible platform that can be adopted, adapted, and integrated across a broader community.
Opening up the ecosystem
UC3’s work has consistently focused on enabling change at scale by working within existing research workflows. When systems align with how research actually happens, and when they interoperate with the broader ecosystem, they can support lasting and meaningful change. The FAIR Station project continues this approach.
We are working toward an open-source platform that acts as a connective layer between fieldwork and the rest of the research lifecycle. By prioritizing openness, modularity, and well-defined interfaces, the FAIR Station project is exploring how this layer can function as a hub that connects with research data management services, persistent identifier infrastructure, repositories, and related systems.
Exactly how this takes shape will be explored with the community. The opportunity is not only to improve individual workflows, but to enable new kinds of connections:
- Clearer links between field stations, research activities, and downstream outputs
- More consistent and reusable metadata generated as part of everyday workflows
- Greater visibility into the impact of place-based research across institutions and regions
- New integrations with tools and services that support data stewardship, publication, and reuse
These are directions, not fixed endpoints. The FAIR Station project is being developed as a space for experimentation, iteration, and collaboration.
Working with the community
From the outset, the FAIR Station project is grounded in partnership. We are engaging field station staff, researchers, and organizations across the open infrastructure landscape to help shape what this effort becomes. Through advisory groups, pilot deployments, and collaborations with complementary services, we aim to ensure that the approach reflects real-world needs and remains adaptable across different contexts. This is especially important as we move from a system that has been successful within the University of California to something that can be used more broadly. Opening up this work is not just a technical step. It is a community process.
Now hiring: help shape what comes next
The FAIR Station project is still taking shape. While there is a strong foundation and a clear direction, many of the most important decisions (how this evolves, how it integrates with other systems, and how it serves different communities) are still ahead. With funding from the Moore Foundation, the FAIR Station team is hiring a Senior Platform & Web Application Engineer through Code for Science & Society (CS&S), our fiscal sponsor and a long-standing partner in supporting open, community-driven infrastructure.
If you are interested in helping shape the FAIR Station project, or know someone who might be, we encourage you to learn more about the position.
UC3 New Year Series: Persistent Identifiers in 2026
CDL’s persistent identifier portfolio, which includes the Research Organization Registry (ROR), EZID, Name-to-Thing (N2T), and the Collaborative Metadata (COMET) initiative, saw strong continued progress and steady technical improvements across its service. Together, these complementary efforts support more connected and efficient research infrastructure, one where persistent identifiers link researchers, institutions, and scholarly outputs in ways that reduce duplication, lower costs, and increase the impact of everyone’s work. As we head into 2026, I’m pleased to share a look at what we accomplished over the past year and what’s coming next.
ROR
ROR is a global, community-led registry of open persistent identifiers for research and funding organizations, operated as a collaborative initiative by the California Digital Library, Crossref, and DataCite. As a free, trusted, and openly available service, ROR has become the standard for organizational identification in the scholarly communications ecosystem. The story of ROR in 2026 is one of rising to meet its place in the world while also making investments to carry the service forward for years to come.
In 2025, ROR processed over 12,000 user-submitted curation requests, a 50% increase over 2024, with trends suggesting continued growth for the year ahead. To meet this rising demand, we are undertaking a top-to-bottom rewrite of our curation review and data publication processes, unifying previously separate workflows and introducing new forms of automation, monitoring, and prioritization. Together, these changes will help support a growing number of curators in attending to the community’s needs while maintaining the high-quality metadata for which ROR is known.
These efforts support strong international growth and adoption of ROR over the past year. Our focus on improving the representation of Japanese organizations in 2025 proved well aligned with broader trends, as the APAC region saw the largest overall increase in adoption of ROR this past year. This work was supported by strengthened partnerships and extensive data reconciliation work with national-level organizations in this region, including new collaborations with government partners in South Korea. We will continue to support this momentum in the APAC region while also pursuing opportunities in other areas of growing adoption, such as Africa and Latin America.
Concurrent with this curation-focused work, ROR will invest in a number of core technology upgrades to ensure its applications and services are stable and performant in the long term. The introduction of a new API caching layer and the efficient single search matching strategy this past year have already yielded significant performance improvements, giving us the opportunity to double down on these investments by moving all of our codebases to the most modern versions of the frameworks and libraries in which they depend. This work will also include a refresh of our UI, migrating it to a modern JavaScript framework that allows us to take full advantage of the ROR API’s features, including its advanced search capabilities.
COMET
The COMET (collaborative metadata initiative, launched in November of 2024, seeks to address critical challenges in the quality and completeness of persistent identifier metadata, with an initial focus on Digital Object Identifiers (DOIs). Currently, only record owners can update DOI metadata, meaning that those with enrichments to contribute must maintain their own improved versions of this metadata in separate systems, duplicating effort and fragmenting the representation of research outputs. COMET addresses this by creating pathways for the community to contribute validated metadata improvements directly to DOI records, unlocking new value and efficiencies at the source.
After an initial taskforce phase that drew together over 100 partners from universities, government organizations, publishers, and infrastructure services, COMET issued a community call to action in March of 2025, soliciting resources to move its work from concept into practice. This was met with responses from our very own UC3, the Public Knowledge Project (PKP), the Centre for Science and Technology Studies (CWTS), and DataCite, all of whom agreed to contribute to moving the project into a pilot phase where its model for community-driven metadata enrichment could be proven out. Work on this new phase began in May 2025 and, over the course of seven months, achieved remarkable results across a set of pilot projects.
These pilots tackled some of the most persistent gaps in DOI metadata, with two focused on the nearly 3-million-work arXiv corpus. The first developed a high-precision affiliation extraction method that produced 12.1 million new affiliation entries, matched to ROR IDs, addressing long-standing barriers to institutional impact tracking. A companion effort bridged arXiv preprints stored in DataCite with published works in Crossref, recovering over 730,000 new preprint-to-publication connections, nearly doubling the total of those previously linked. A separate pilot, conducted with European Molecular Biology Laboratory (EMBL) and Wageningen University & Research, tested a lightweight automated reconciliation of institutional Current Research Information System (CRIS) data against metadata in OpenAlex, an open catalog of the global research system. This reconciliation strategy returned approximately 90% of each institution’s manually-curated works while also discovering many not previously found through this curation. Where reconciliation failed, the process also surfaced specific metadata issues that resulted in the gaps, demonstrating that this automated method could match and even improve upon manual curation efforts with a fraction of the time and effort.
Taken together, these pilots confirmed that community-coordinated enrichment work, built around shared methods and PID integration pathways, can produce trusted, reusable outputs at scale. In 2026, COMET will focus on formalizing the processes and structures that emerged from these pilots while extending its collaborations to new partners and domains. To stay apprised of future work, subscribe to COMET’s email list to receive up-to-date news or follow its LinkedIn page for updates.
EZID, ARKs, and N2T
EZID and N2T are complementary persistent identifier services that enable reliable, long-term access to research outputs. EZID provides identifier creation and management services focused on ARKs and DOIs, while N2T serves as a global resolver that ensures identifiers remain reliable and actionable over time. UC3 also provides the development resources that support the creation and management of Name Assigning Authority Numbers (NAANs), the organizational identifiers that underpin all of global ARK resolution.
In 2025, EZID completed a series of updates to its user interface to bring it into compliance with modern accessibility standards, ensuring that all users can effectively make use of the service. We also added support for the new DataCite schema, v4.6, keeping EZID up-to-date with the latest standards in DOI metadata management. Alongside these improvements, we made significant investments in NAAN curation workflows, introducing new automation that allows for more efficient and responsive management of these identifiers and their metadata.
Following the successful rewrite of N2T as a modern Python service, we are now working on moving it into a containerized deployment setup, an effort that is part of a broader push across both EZID and N2T toward modern deployment practices that support continuous integration and delivery. Together with adding support for the new DataCite schema coming later this year, these investments will further improve reliability, scalability, and operational efficiency across our services.
As I hope this all conveys, it has never been a more exciting time to both help build and take part in the persistent identifier ecosystem. Here’s to 2026 and all the promising work ahead for the University of California community and beyond!
UC3 New Year Series: Data Management Planning in 2026
Welcome to the second post of UC3’s New Year blog post series, where different services of UC3 take a look at the coming year. If you haven’t already read it, check out the first one on digital preservation.
Over in the world of Data Management Planning, we’ve got a lot of exciting work this year to share!
DMP Tool Rebuild
Our main project continues to be working on the rebuild of the DMP Tool. While we initially hoped to have it ready early this year, we’re now targeting the summer of 2026. This gives us more time to make sure it’s at a high level of quality, and also releases it at a time that will hopefully be less disruptive to people who teach classes using the DMP Tool. There’s a chance it will take longer than the summer though – we’re focused on quality over speed.
We’ve done 3 rounds of user testing so far on the site, and each time has given us a lot of valuable information. We’ve gotten a lot of positive feedback about new features we will be offering, such as alias email addresses, adding collaborators to templates, a revamped API, and much more. Other changes, though, have caused some confusion for people used to the current tool, and through testing we have found opportunities to improve the workflow and usability of the new site. These are the types of changes that mean the rebuild will take longer than initially planned to complete, but we think are worth the time to get right.

To keep updates about the rebuild in one place, we have a Rebuild Hub page on our blog. We’ll keep this page up to date with the latest information about the release date, FAQ, status updates, and more. We plan to make posts leading up to the new release showing the major changes and giving guidance to make the transition as seamless as possible. If you’d like to help with testing at any point, please sign up for our user panel to get invitations to future feedback sessions.
As we’ve said before, we’re limiting updates to the current tool so we can focus our limited resources on the rebuild; but of course we also want to keep the tool live and helpful during the transition. We’re fixing any major issues that come up, such as keeping it up to date with new ROR API and schema, and addressing user tickets as quickly as possible. We are trying to keep funder templates up to date as well, but the frequency of new information and potential changes has made it difficult to perfectly capture all updates to federal guidelines. We want to make sure we have the most relevant information possible on the tool without changing templates too often (as that can lose organization guidance), so we’ve been collecting updates from our Editorial Board members for a template release in the near future. If you see any instances where a template in our tool does not match a funder template, please reach to us by email so we can get it corrected.
Get Involved with API Integrations
With our rebuild is coming a complete revamped API to take advantage of our new machine-actionable functionality. We’re currently looking for partners that would like early access to our new API in order to develop new integrations for our rebuild. Our goal is that the new API can do anything the user interface can do, which means the sky (or more relevant, the cloud) is the limit for possible tools. If you’ve been wanting to connect to our API for some sort of automation that our current API did not offer the capability for, we’d love to hear from you. You can hear more about past pilot integrations and how to work with our API at this recording of our webinar from the Machine-Actional Plans pilot project. We’ll be following the common API standard being developed with the Research Data Alliance, meaning many integrations with our tool should work for other DMP service providers as well. If you have an idea for an integration you’d like to build on our new API, please reach out to dmptool@ucop.edu!
Matching to Published Research Outputs
We’ve talked before about a major project to use machine learning models to help match DMPs to their eventual research outputs, like datasets and software publications, to help make data from published DMPs easier to find and re-use. This work has continued and we plan to release it with the rebuilt DMP Tool. Since our last update, we’ve made some significant steps towards this goal, including:
- Moving the infrastructure onto our own servers to prepare for integration into the DMP Tool
- Adding new sources of data, such as grant award pages that list published outputs
- Getting the normalized corpus into OpenSearch to aid us in the matching process
- Expanding our ground truth dataset of true matches and non-matches to help test our matching algorithm
- Utilizing a Learning to Rank model that will improve over time as it learns from accepted and rejected matches
- Building out the user interface for how users will see potential matches and accept or reject them
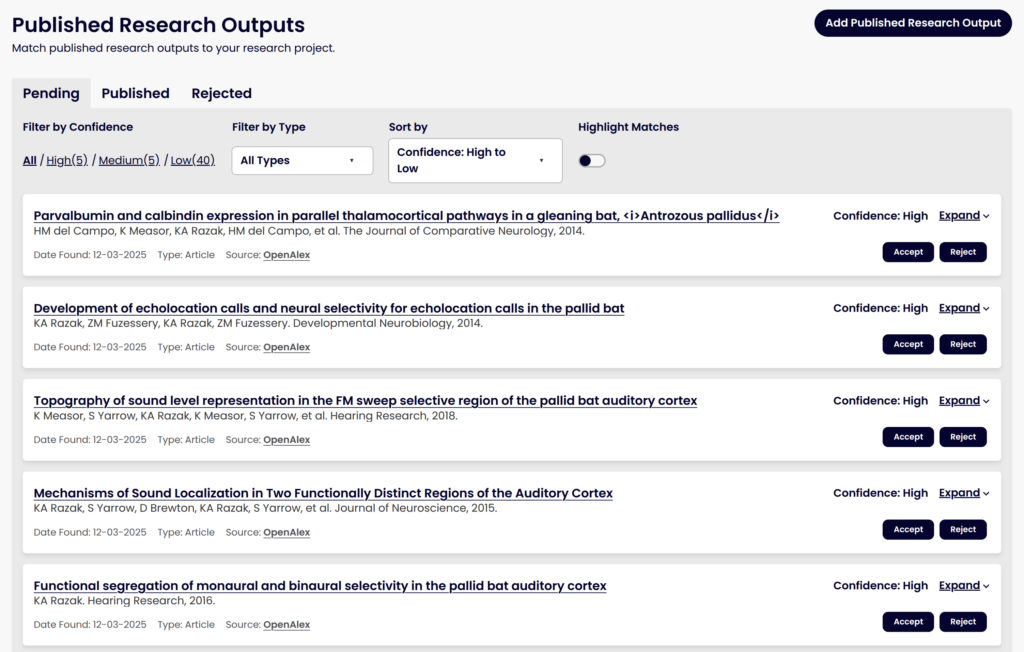
Improvements we plan to work on over 2026 include:
- Adding in related outputs based on accepted outputs (i.e., finding matches to any Accepted works in addition to matching against the DMP itself)
- Looking at options to improve the matching algorithm, such as vector search with an embedding model
- Working with the COMET team on tooling that can extract award IDs from published outputs, which will improve the quality of matching to DMPs that include an award ID
We’re excited for people to get to use this tool with the rebuild and start accepting and rejecting potential matches so we can learn from this and improve the matching algorithm further over time. People will also be able to manually add DOIs as research outputs, like they can on the current tool, which will also help train the model over time on what we missed as potential matches. This will be available for all DMPs that have been published, i.e., registered for a DMP ID. Accepted works will be added to the metadata for the plan as related identifiers.
DMP Chef
Another exciting area we’re exploring is the use of generative AI to assist in writing Data Management Plans. We’ve partnered with the FAIR Data Innovations Hub to work on the DMP Chef, a project to explore using large language models (LLMs) to draft DMPs. Our goal is not to take away the key decisions in data management planning from a researcher, but instead to simplify the process as much as possible by asking a few critical questions, combining that responses with funder requirements that need to be met, and using those to produce a draft of a DMP for their review and edits.
We have promising early results, with both automated statistics and human evaluations showing the LLM-drafted DMPs can be comprehensive, accurate, and follow best practices. Commercial models are performing better than the open-source models, but since we want to remain open-source, we’re looking at ways to improve the open-source models through additional retrieval augmented generation and other options. And we’ll be testing carefully how accurate and helpful the output is, as well as looking at ways to help ensure researchers read and edit the plan as needed, rather than just accept the output right away.
| DMP Source | Overall Satisfaction rating (1-5) | Average Error Count per DMP | Accuracy in guessing LLM vs Human |
|---|---|---|---|
| Human | 3.1 | 7.2 | 65% |
| LLMs (combined) | 3.4 | 4.9 | 43% |
| Llama 3.3 | 2.6 | 7.5 | 70% |
| GPT-4.1 | 4.2 | 2.3 | 15% |
Over the course of 2026, we plan to keep testing and improving this model, starting with NIH and NSF plans. The ultimate goal is a general use model that can be used within the DMP Tool for any funder to get a first draft of either a whole DMP or specific sections a researcher is struggling with. We have a working prototype tool for DMP generation we will use for testing purposes, with integration into the DMP Tool planned for further out. If you’d like to be part of testing out this new tool, please sign up for our user panel.
Thanks for reading about our major initiatives for the year! Keep an eye out on this space for the next post in our series, about our 2026 plans for persistent identifiers.
We are grateful to the Institute of Museum and Library Services, the National Science Foundation, and the Chan Zuckerberg Initiative for each supporting core components of these initiatives.
UC3 New Year Series: Digital Preservation in 2026
At UC3, we’re dedicated to advancing the fields of digital curation, digital preservation, and open data practices. Over the years, we’ve built and supported a range of services and actively led and collaborated on initiatives to open scholarship. With this in mind, we’re kicking off a new series of blog posts to highlight our core areas of work and where we’re heading in 2026.
Welcome to UC3’s 2026 New Year blog post series! This first post dives into the team’s engagement with all things digital preservation, along with its further development of CDL’s digital preservation repository, Merritt.
- On the repository front, we’ll discuss how the accomplishments of 2025 have aligned us to complete a major revamp of repository infrastructure in 2026 that promotes security best practices, eases management and reduces environmental impact while also addressing varying rates of deposit.
- With regard to community and campus engagement, we’ll review the outputs of the Digital Preservation Working Group and how these can promote new and enhanced practices and collaboration surrounding the preservation of digital materials.
- We’ll also note engagement in an external, Library of Congress-driven effort surrounding content provenance and authenticity that could benefit publications being preserved in Merritt.
- And, specifically for the Merritt team, we’ll talk about what it means for us to again take on the task of renewing our CoreTrustSeal certification.
Moving Merritt into the Realm of Containerization
Although our team has always been improving the Merritt repository with an eye on operational efficiency, security, transparency and durability, it was not until 2025 that we really entered the beginning of a major paradigm shift with how the system functions. This shift entails movement of Merritt’s microservices and queueing system into a fully containerized state.
What’s in a container and why are we making this shift?
In essence, a container is a fully functional and portable cloud computing environment that surrounds an application. Inside a container, an application such as Merritt’s Ingest microservice has all of the resources it needs to run – including a common operating system, an allocation of memory, configuration files and any required software libraries and dependencies. As a result, the new Merritt system will be composed of a series of small, light-weight, secure containers that complete processing significant amounts of incoming, archival content more quickly.
That’s also to say, going forward, each Merritt service will no longer operate on a customized, often expensive AWS Elastic Compute Cloud (EC2) instance. Instead, services will operate in containers that are orchestrated (i.e. automatically managed) by Amazon’s Elastic Container Service (ECS).
There are numerous advantages of running Merritt using this new strategy and infrastructure. First and foremost, it allows microservices to scale according to the activity of depositors. In other words, when multiple depositors have sent multi-gigabyte or multi-terrabyte batches to ingest, Merritt’s Ingest and Storage microservices will scale up as needed – meaning more containers that operate the software that performs ingest and storage operations will be started automatically.
And, as opposed to manually requesting additional, more costly EC2 instances be instantiated temporarily by DevOps, each new container spins up via ECS automatically in minutes – with the latest operating system and dependency updates already in place. Just as importantly, once the load on these services reduces, unneeded containers will be automatically spun down. Doing so keeps the repository’s overall footprint as small as possible. Fewer unused compute resources means less power consumption and heat generation at data centers, and in turn lowered impact on the environment.
Given all these benefits, we are incredibly excited to be within reach of our containerization goal. Merritt’s administrative service has already been containerized and its UI is next on the list. After that, we’ll move Merritt’s Audit and Replication services to containers, followed by Inventory, Ingest, Storage and finally ZooKeeper. Throughout the year, we’ll keep you informed of our progress through upcoming, monthly CDL INFO newsletter posts.
Community Engagement
At the end of 2025, the UC Libraries Digital Preservation Working Group (DPWG) completed its charge. By year’s end the group had submitted both a comprehensive gap analysis and a new digital preservation framework to the Direction and Oversight Committee (DOC) in final form.
The gap analysis, based on the Digital Preservation Coalition’s Rapid Assessment Model (DPC RAM), allowed the team to evaluate to what degree main campus libraries met multiple criteria considered key to good digital preservation practices. The gap analysis subgroup effectively transformed the RAM maturity model into a survey instrument, gathering over 50 responses from participants.
As the gap analysis was underway, a separate DPWG subgroup reviewed existing digital preservation frameworks from a number academic institutions and consortia. This group evaluated which framework elements were most applicable to the needs of UC campus libraries. Frameworks and associated documentation from ICPSR, University of Washington Libraries, Yale, Northwestern, and Harvard, among others, including our own campuses at San Diego and Santa Cruz were explored.
What became evident during this process was that the forthcoming framework needed to be practicable by a large number of independently operating libraries with mixed resources and varying priorities – but with the added requirement to report back to a critical, long standing governance structure. In this case, the University Committee on Library and Scholarly Communication, or UCOLASC.
Through an iterative process that was informed by gap analysis results, a new digital preservation framework was created. Its key components include a range of operating principles, identification of potential campus designees and discussion surrounding shared services – specifically with a slant towards development involving collaborative design, transparent governance and inclusiveness of campus library voices.
Throughout the year, we look forward to collaborating with campus libraries on the introduction of the new framework and how they can potentially take advantage of what it has to offer.
Please note that both the gap analysis and framework have not yet been published, but links to them will be made available through this site when they become available!
Coalition for Content Provenance and Authenticity (C2PA)
A few years ago a group of major players in the technology and media space including Adobe, Microsoft, Google, BBC and Sony began collaboration around what would become a public specification for the promotion of content authenticity and provenance. This specification and its implementation by vendors and organizations strives to provide the means to include a living manifest of metadata in digital materials. A C2PA manifest can record when a digital asset first came to be along with myriad changes that span the asset’s lifecycle. Such structured and secure metadata is purposed to record the provenance of the item while also describing the ongoing changes made to it by actors, be they human or machine. In essence, through purposeful metadata handling, it becomes possible to identify if the asset was altered or utilized in a fashion that was not intended by its creator and subsequent users.
Through engagement with the C2PA for G+LAM working group driven by members of the Library of Congress, the Merritt team has contributed to the development of a newly defined C2PA use case for Open Access journal publications, as well as a forthcoming, public call-to-action white paper addressing high-level issues related to AI and content authenticity and provenance. This latter deliverable is intended for cultural heritage administrators and practitioners. It will cover “potential risks and opportunities presented by recent AI technologies and outline potential directions for future collaborative research and experimental applications.”
Stay tuned, as a draft should be posted for public comment in February.
Merritt’s CoreTrustSeal (re)Certification
This year we will re-apply for Merritt’s certification by CoreTrustSeal (CTS). At the same time, 2026 marks the beginning of a standard three year period where revised CTS requirements come into play. The upshot being that we will need to address many more requirements in comparison to Merritt’s last certification – which is a good thing!
In a similar vein the Merritt service manager (myself) has been part of the CTS Assembly of Reviewers, a group of nearly 100 individuals responsible for reviewing CTS submissions from repositories around the world. Which also means I’m very much looking forward to going through the exercise of revamping our application and all of the supporting information that’s needed for a successful certification. An internal audit such as this one, driven by an organization with international roots and a vast amount of combined experience presents an incredibly beneficial opportunity to introspect. And through introspection, we’ll better our repository and the services it provides for our colleagues across the entire UC system.
Again – welcome to UC3’s 2026 New Year Series. The next post on Data Management Plans and DMP Tool should arrive next week!
Why Award DOIs Matter: Strengthening Discovery Across UC’s Funding Programs
The Research Grants Program Office (RGPO) at the University of California Office of the President manages one of the UC system’s most impactful research portfolios, comprising over $100 million in yearly awards across programs such as the California Breast Cancer Research Program and the California HIV/AIDS Program. These diverse and impactful funding activities are complemented by rigorous internal data practices for tracking their impact, including providing rich and detailed descriptions of these activities in their public-facing grants database.
As persistent identifier (PID) enthusiasts, the availability of this high-quality data source immediately presented itself to the UC3 team as a unique opportunity. By leveraging the RGPO’s comprehensive metadata to generate award DOIs in DataCite, we could bridge the gap between their accounting and the larger research ecosystem, broadcasting the full scope of RGPO’s impact to this even larger audience.
Why DOIs?
Registering DOIs for awards provides a high-level view of all of the RGPOs’ work across its funding programs, describing them in a unified fashion using the DataCite schema, which provides a persistent, machine-readable reference and improves the visibility of these funding activities. By assigning DOIs, RGPO awards become connected to the broader persistent identifier ecosystem, meaning that other systems can easily discover, link to, and reuse information about these awards and their associated research outputs. Ultimately, this helps close gaps between internal and external systems, creating a more comprehensive picture of the University of California’s impact and RGPO’s role in that success.
How we did it
We worked closely with the DataCite team to analyze existing practices for representing awards in their schema, ensuring that everything was modeled correctly. This included identifying and resolving inconsistencies in representations.
Once those issues were resolved and the model was set, the registration process itself was straightforward:
- We mapped RGPO award data to the DataCite schema.
- Added ROR IDs for the funder (University of California Office of the President) and other relevant entities.
- Linked research outputs to the awards by including DOIs for their related works.
- Generated the XML for the award records and registered via the DataCite API.
- Finally, we provided the RGPO with a report of these registrations so that the DOIs could be integrated back into the RGPO’s grants database.
What’s Next: Automation and Research Graph Connections
We’re now focused on two primary next steps:
1. We’re working to automate more of the DOI registration and update processes to ensure new or changed awards are registered more frequently than the current manual updates.
2. We’re collaborating with OpenAlex on their new grant-funded project to incorporate better and more complete funding metadata into OpenAlex’s scholarly graph. As one of the first registrants of award DOIs with DataCite, OpenAlex is using CDL’s detailed account of the RGPO’s funding activities to model the ingestion and mapping of DataCite award DOIs more broadly.
Our efforts open RGPO grant projects to further enrichment of metadata and connections. This work includes matching grant-funded research outputs with their corresponding award DOIs, both by matching unstructured publication references in the funder metadata and by mining full-text publications to identify links that were not explicitly asserted in their DOI metadata. The goal is that once these connections are identified, they can also be incorporated back into the award DOIs and DataCite, thereby making their description more comprehensive and complete.
Our hope is that this work demonstrates the value of PIDs for awards and encourages other funders to adopt a similar approach. Registering award DOIs doesn’t just improve local data quality; it strengthens global research infrastructure and helps make the impact of publicly funded research more visible and more connected.
Exploring How AI Can Help Research Data Management
At UC3, several of our latest initiatives involve integrating AI tools, with a particular focus on improving metadata and assisting researchers with creating best practice DMPs.
A clear philosophy guides UC3’s approach to the use of generative AI: addressing researchers’ and the broader research community’s needs, keeping humans as the authority, complementing human work for scale and efficiency, and prioritizing open-source solutions where possible.
Improving ROR Metadata
One key application of AI we are exploring is enhancing the quality and scale of our metadata curation activities, including those for the Research Organization Registry (ROR). ROR, a widely adopted persistent identifier service for research organizations, operates on a model where anyone can submit a request to add or update its records. This community-focused approach to curation has allowed ROR to grow rapidly by gathering diverse and valuable feedback from a global userbase. However, as one might expect with crowd-sourced data, it also has inherent complexities that require special attention to maintain consistency and quality.
AI helps by taking these diverse user inputs and automatically transforming them into clean, structured, authoritative outputs in the ROR dataset. For adding records to the registry, this automation seamlessly handles data standardization, formatting, and enrichment tasks that would otherwise require specialized logic and manual intervention to achieve. For updates to the registry, AI can transform natural language descriptions of desired changes into structured modifications, described using ROR’s data model. These interventions have dramatically accelerated ROR’s request processing ability, enabling the service to now efficiently handle its growing request volume and process over 1,000 user-submitted requests per month.
Despite these advances, achieving 100% accuracy or completeness with these methods is neither possible nor desirable. Instead, we choose to pursue hybrid approaches that balance the efficiency and scalability of GenAI with the measured judgment and domain expertise that only human curators can provide. In doing so, we can embrace both innovation and authoritative oversight, allowing ROR to further grow in its position as a reliable, community-driven infrastructure, in service to the complex needs of the global research ecosystem.
DMP Chef: Exploring AI-powered DMP Generation
Another example of our AI exploration is “DMP Chef,” a large language model (LLM) based DMP generator. We are in the initial stages of this work, partnering with the California Medical Innovations Institute (CalMI2) to develop a new tool that allows researchers to provide simple descriptions of their work, from which the DMP Chef can generate a draft DMP. We are currently developing this tool to work with NIH DMPs and plan to follow up on this work by working with NSF and other templates.
The current process involves asking researchers for a short description of their study and the types of data they plan to collect, then using a detailed prompt to have the LLM draft an initial DMP using NIH’s template for review. To test the initial quality, we used the NIH exemplar DMP, extracting the study design and data types from Element 1, and then feeding that information into the tool. We compared the generated output with the actual DMP section by section. Our next step is to recruit data librarians to review these generated DMPs for quality and comprehensiveness.
We’re seeing some moderate initial success with off-the-shelf LLM models, including open-source models, and plan to continue working on refining the quality by exploring options such as asking additional questions to the researcher, generating sections to separate, and feeding the LLM additional policy documents. Our goal is to help create an initial draft of a high-quality plan that researchers can then refine to their needs, suggesting best practice repositories and standards based on their specific data.
Matching Related Works: Connecting Plans to Outputs
We’re also developing new tools to automatically connect DMPs to the research outputs they describe, such as datasets, articles, and software. These new connections improve the discoverability of research data and make it easier for researchers, funders, and administrators to see the complete picture of a project’s outputs. Our approach combines structured metadata from maDMPs with information from sources like DataCite, Crossref, OpenAlex, and the Make Data Count Citation Corpus. We utilize machine learning, incorporating embeddings generated by large language models and vector similarity search, to compare the text from the title and abstract of a DMP with those descriptive fields within the datasets, rather than relying solely on metadata for authors and funders. A human reviewer then confirms the matches to ensure accuracy and reduce the manual reporting burden on researchers. You can read more about this feature at the DMP Tool Blog.
UC3’s AI initiatives are focused on making research data easier to find, connect, and trust. By pairing AI-driven efficiencies with human expertise, we can accelerate workflows while maintaining the accuracy, transparency, and trust essential to research.
Why CDL Is Investing in COMET: A Community Centered Path to Richer Metadata
When the California Digital Library (CDL) signed the Barcelona Declaration in April 2025, it marked a deeper institutional commitment to building open and community-led research infrastructure. At the heart of this commitment is a recognition that metadata is not a passive byproduct of scholarship, but an active force that shapes how research is discovered, connected, cited, and reused. To build an ecosystem where metadata reflects the values of openness, equity, and trust, we must ensure that its stewardship is shared, inclusive, and sustainable.
This is why CDL’s University of California Curation Center (UC3) program is investing in COMET (Collaborative Metadata Enrichment Taskforce). COMET is both a vision and a framework for creating a healthier metadata ecosystem, where persistent identifiers are enriched and maintained through transparent, distributed workflows that engage the full research community. The principles below represent the building blocks of the COMET model and the foundation of CDL’s participation therein:
- Metadata Must Be Open and Reliable: As with our many efforts to make metadata freely accessible and machine-readable, COMET centers its work on improving completeness, consistency, and interoperability across the persistent identifier (PID) ecosystem. By supporting basic PID metadata elements (e.g., title, author affiliations, publication dates) to be made openly available, CDL aims to dismantle paywalled research environments, ensuring that even the most basic scholarly facts are free, reusable, and trustworthy
- Shared Stewardship Reduces Silos and Gaps: CDL understands the burden metadata creators face: original depositors often lack the resources to enrich records. Yet researchers, funders, and institutions have knowledge that could fill those gaps. COMET’s community-curation model is modeled after the success of ROR, which distributes responsibility for metadata improvements across the ecosystem
CDL’s engagement with COMET reflects its “pathways” approach: working within existing metadata systems while facilitating new, collaborative routes for enrichment and shared stewardship across the ecosystem. - Community Governance Builds Trust and Quality: COMET is not proprietary. It prioritizes inclusive, transparent governance—publishing standards, embracing equitable practices, and grounding changes in real-world use cases. CDL’s track record with community-governed PID systems (Crossref, DataCite, ROR) aligns perfectly with COMET’s ethos.
How COMET Emerged and CDL’s Participation
COMET emerged from a shared realization across the scholarly infrastructure community: if we want metadata that is trustworthy, complete, and actionable, we need to design systems that allow more people to contribute to it and more institutions to shape its governance. This vision came into sharper focus during a series of workshops at FORCE2024 held in Los Angeles and the Barcelona Declaration Community Meeting held in Paris, where participants from across disciplines and sectors gathered to discuss new models for collaborative metadata curation. These sessions surfaced a common theme: metadata enrichment can’t be sustained by individual repositories or publishers alone. What’s needed is a coordinated, community-powered model that invites researchers, libraries, funders, and infrastructure providers to play an active role in improving the quality of metadata tied to persistent identifiers.
Out of these conversations, COMET was born. By early 2025, COMET had evolved into a formal FORCE11 Project and culminated in an open “Community Call to Action” that invited broad participation in shaping workflows, tools, and governance models for metadata enrichment.
CDL was an early and enthusiastic supporter because the vision aligned with our mission and we see an opportunity to help bring it to life. Our involvement isn’t passive. CDL’s UC3 program brings more than two decades of experience in digital curation, persistent identifier infrastructure, and open scholarly systems. We contribute governance know-how, technical insight from our work on initiatives like EZID, Crossref, ROR, and DataCite, and convening power across academic and infrastructure communities. We also see COMET as a proving ground: a space to pilot scalable, community-led metadata workflows that can extend across institutions, repositories, and disciplines.
For CDL, joining COMET is a continuation of our long-standing commitment to open, shared infrastructure and collective progress. It’s an investment in a future where metadata is openly enriched, transparently verified, and valued by the very communities who depend on it.
What Community Participation Means
When libraries and institutions like CDL engage with efforts like COMET, the benefits extend far beyond improved metadata. Our participation brings a deep commitment to equity, transparency, and public stewardship with values that help shape infrastructure for the public good. By contributing expertise in curation, governance, and metadata standards, libraries ensure that research information is more complete, discoverable, and reusable across repositories, researcher profiles, and campus systems.
Shared governance is a central feature of COMET’s approach, and institutional involvement helps ensure that decisions reflect the needs of a global, diverse, distributed community. When we engage in this work, they align their local priorities with broader efforts to create trustworthy, persistent, and openly governed metadata. This alignment reduces redundancy, increases impact, and builds capacity for meaningful contributions across the ecosystem.
But the benefits of this work aren’t just at the institutional level. For researchers and end users, the results are tangible: better discovery, clearer provenance, and richer metadata that supports citation, reuse, and reproducibility. And for funders, repositories, and service providers, this community-driven model offers a scalable alternative to siloed or proprietary solutions that emphasize interoperability, transparency, and accountability.
That’s why we believe that COMET offers more than just a framework for metadata enrichment. It provides an opportunity for us to embody our mission-driven values and help build the connective infrastructure that research depends on. For CDL, supporting COMET is a way to double down on its long-standing commitment to open, community-led infrastructure. It’s about creating shared pathways to trust, equity, and impact where metadata isn’t hidden or locked down, but serves as the connective tissue for discovery and collaboration.