(index page)
UC3 New Year Series: Data Publishing at CDL in 2025
Structured, well-documented, and FAIR-aligned data is the foundation of effective research dissemination. However, data publishing activities have often focused on the last step in the research process. This puts energy on helping researchers clean up disorganized data sets and placing them in repositories. While this is essential to ensuring accessibility and preservation of important data outputs, it is also important to connect the dots and address the underlying issues that lead to poor data quality in the first place. Our previous development work and continuing membership with Dryad are great examples of this commitment to supporting well-formatted deposits. However, it has also always been the strategy of the UC3 data publishing team to invest in people through training, comprehensive documentation, institutional support and policies, and innovative tools. Our goal is to connect those dots and help empower the research community with the skills and knowledge to create high-quality, well-structured data from the outset.
In 2025, we aim to create a more open, transparent, and sustainable data-sharing future by combining emerging technologies with structured training programs. This dual approach improves data deposit quality and empowers researchers to contribute to a more efficient data-publishing ecosystem.
AI Tools for Data Publishing
Conversations with repository managers often highlight recurring challenges: incomplete documentation, missing README files, or data files that don’t match metadata standards. Automated “nudges” can catch such issues at the point of deposit. The vision is for AI-based systems to serve as virtual coaches that flag inconsistencies and as active collaborators capable of implementing necessary changes where appropriate. These tools will be able to modify metadata directly, generate appropriate README files, and restructure dataset instructions when needed—transforming how researchers prepare and deposit their data.
One promising component of our 2025 strategy involves the development of AI-assisted curation tools, which we’ve begun exploring to provide researchers real-time feedback on their data deposits. This approach leverages artificial intelligence to identify potential metadata, documentation, and formatting issues before submission. However, we won’t be covering this topic in detail here. Those interested in our AI curation initiatives, please refer to our previous article, in which we discussed this thoroughly.
In this post, we highlight CDL’s collaboration with The Carpentries as a key component of the UC3 data publishing strategy for 2025, emphasizing the human side of our approach: training. The Carpentries teaches foundational coding and data science skills to researchers worldwide, and through our partnership, we directly address the skills gap in metadata, documentation, and data formatting.
Training Translates to Broader Impact
Good data practices are part of many successful interdisciplinary collaborations. For example, after the Deepwater Horizon spill in the Gulf of Mexico, researchers in fields as varied as biology, oceanography, engineering, and socioeconomics exploited consistent metadata standards to share thousands of datasets seamlessly. That synergy is best achieved when data management principles are embedded long before a crisis or urgent need arises. Planting the seeds of data literacy in labs and classrooms allows institutions to sidestep the friction and duplicative efforts that often accompany cross-institutional projects.
Robust training programs also help teams stay nimble when policies shift. As mandates continue to change—whether through federal agencies or international collaborations—researchers grounded in best practices can adapt quickly, avoiding costly do-overs. In this sense, the cost-effectiveness of up-front training becomes an investment in a more flexible, forward-looking data ecosystem.
Why Training Makes Data Publishing Easier (and Less Costly)
Early exposure to best practices in data management often prevents unnecessary clean-up and steep learning curves later on in a researcher’s career. This observation was echoed in discussions at a recent Earth Science Information Partners (ESIP) meeting, where a central theme was the value of weaving data skills into formal coursework—rather than treating them as optional add-ons for already overworked researchers. Students who learn these concepts in undergraduate or graduate courses, sometimes through a single assignment requiring a formal data management plan, become more adept at producing coherent, reusable datasets.
In many cases, the hands-on philosophy developed by The Carpentries aligns with such classroom activities. Whether using version control for a small-scale project or learning to structure metadata for a mock submission to a repository, these experiences reduce the likelihood of encountering major data-quality issues down the line. Once researchers join labs and undertake funded projects, they have the required knowledge to meet evolving mandates without incurring frantic, last-minute adjustments.
The Carpentries and CDL: A Long-Standing Partnership
For over a decade, the CDL has worked with The Carpentries to refine curricula on coding, documentation, and data management best practices. A 2017 grant from the Institute of Museum and Library Services (IMLS) helped expand “Library Carpentry,” allowing librarians to participate in curation actively. Last year, we received another IMLS award to help the Carpentries scale their operations and curriculum. Over the years, UC3 staff have been closely involved in shaping these workshops, hosting sessions, and serving on governance councils to promote a broader culture of responsible data stewardship.
One of the main strengths of The Carpentries’ model is its train-the-trainer approach. Seeding new workshops across campuses and disciplines is possible by certifying volunteer instructors within organizations. This approach has found synergy with our participation in the Generalist Repository Ecosystem Initiative (GREI), a collaborative effort bringing together seven major generalist repositories, including Zenodo, Dryad, Vivli, Center for Open Science, and Dataverse. Through GREI, we’re expanding the reach and impact of data publishing best practices across diverse repository infrastructures.
Under the auspices of the GREI project, we’re working with selected Carpentries modules to address specific data publishing challenges across multiple repository environments. In 2025, we’ll pilot these modified modules in workshops to gain practical teaching experience with this GREI-relevant curriculum. This field testing will provide valuable instructor and participant feedback, allowing us to refine the content and delivery methods. This iterative approach ensures that these modules will ultimately integrate seamlessly into the broader Carpentries curriculum, creating sustainable resources that address the complexities of modern data publishing.
Moving Forward in 2025
High-quality data deposits rarely emerge by accident, they require intentional investment in training, documentation, institutional support, and tools. At UC3, we take a holistic approach, recognizing that creating better datasets goes beyond technical solutions – it demands strategic investments across the entire research data lifecycle.
By strengthening training programs, refining repository workflows, and making learning resources widely accessible, we help researchers at all levels produce well-structured, reusable data. Our ongoing collaborations with The Carpentries and GREI ensure that best practices continue to evolve alongside the research community’s needs. With these efforts, “deposit-ready data” can become the standard rather than the exception, reducing inefficiencies and accelerating scientific discovery. As we move through 2025 and beyond, our focus remains clear: building a sustainable, scalable, and human-centered data publishing ecosystem that empowers researchers and institutions alike
UC3 New Year Series: Persistent Identifiers at CDL in 2025
CDL’s persistent identifier portfolio, which includes the Research Organization Registry (ROR), EZID, Name-to-Thing (N2T), and the new Collaborative Metadata Enrichment Taskforce (COMET) initiative, had a busy and productive year in 2024, seeing record adoption, interest, and making significant technical improvements across its services. These complementary work streams help build a more rational, networked, and efficient research ecosystem – one where persistent identifiers allow for seamless connections between researchers, institutions, and scholarly outputs, reducing redundant efforts, unnecessary costs, and making everyone’s work more visible and impactful. As we move into 2025, I’m excited to bring you a look ahead into what we have planned for this year.
ROR
ROR is a global, community-led registry of open persistent identifiers for research and funding organizations, operated as a collaborative initiative by the California Digital Library, Crossref, and DataCite. As a trusted, free, and openly available service, ROR has become the standard for organizational identification in the scholarly communications ecosystem. The story of ROR in 2025 will be seizing the opportunities provided by this widespread adoption with better performance, improved services, and higher-quality data.
This work will begin with a Q1 launch of a new and improved version of our affiliation matching service, which has been battle-tested in OpenAlex and used to make millions of new connections between authors, works, and institutions. From here, we will further improve our API’s performance by implementing response caching for repeat requests, speeding up response times and reducing overall resource usage. Once this is complete, we will round things out by implementing a client identification system, allowing ROR to better manage its traffic, while also keeping our API services available at the same generous level of public access.

Concurrent with this technical work, ROR will pursue a number of improvements to the quality and completeness of its data, building on work done in 2024, as well as embracing new and emerging opportunities. This will include many regional improvement efforts, with work already underway in Portugal and Japan, better representation of publishers, society organizations and funders, as well as the addition of new external identifiers and improved domain field coverage in support of all of these efforts. ROR will also continue to refine its curation processes to meet the growing needs of its community. In 2024, ROR processed over 8,000 curation requests—a 44% increase from 2023—with trends indicating that we should expect to receive 1,000 requests per month by year’s end. Our goal is to continue publishing the same, high quality data on our monthly release schedule, even in the face of this increased demand!
EZID and N2T
EZID and N2T are complementary persistent identifier services that enable reliable, long-term access to research outputs. EZID provides identifier creation and management services focused on ARKs and DOIs, while N2T serves as a global resolver that ensures identifiers remain reliable and actionable over time.
In 2024, EZID was sharply focused on improving its reliability and performance. This included moving to OpenSearch to power our search functionality and rewriting many of our background jobs and database queries to increase their speed and efficiency. This work has resulted in a more stable and high-performing service, capable of handling the large increase in traffic that resulted from EZID assuming resolution functionality for its own ARK identifiers. Building from this foundation, in 2025, we will continue to optimize our underlying systems, while also adding support for DataCite schema v4.6 and improving EZID’s user interface. Our UI updates will be focused on improving the application’s accessibility, such that all users can effectively manage their persistent identifiers. These coordinated improvements will guarantee that EZID remains a dependable and inclusive platform for persistent identifier management.
Alongside EZID’s improvements, we completed another major milestone in 2024: rebuilding N2T as a modern Python service. With the new flexibility and performance this provides, our 2025 plans include rolling out additional service enhancements for N2T that will better support ARK curation workflows, adding public-facing resolution statistics, and fully deprecating the legacy instance of this application. This work will continue to strengthen N2T’s role as essential infrastructure for all the great identifier usage that occurs outside and in parallel to the DOI ecosystem.
COMET
The COMET initiative, launched in November of 2024, seeks to address a critical problem in DOI metadata management. Currently, only record owners can update DOI metadata, even when others have improvements to contribute. This leads organizations to maintain their own enhanced versions of the same records in separate systems, resulting in duplicated effort and inconsistent representations of research outputs, both individually and in aggregate. COMET’s solution is to create an open framework that allows the community to contribute validated metadata improvements directly to DOI records, unlocking tremendous new value and efficiencies at the sources of this metadata.
To date, COMET has brought together experts from publishers, libraries, funding organizations, and infrastructure services in a series of listening sessions focused on the vision, product definition, and governance model for a service that would realize its goals. In March 2025, these efforts will culminate in a community call-to-action, soliciting partnerships, funding, and other resources to help build this service. Subscribe to COMET’s email list to receive up-to-date news or follow its LinkedIn page for updates.
As I hope this all conveys, it has never been a better, more energizing time to both help build and participate in the persistent identifier ecosystem. Here’s to 2025 and all the exciting work ahead for the UC3 and the scholarly communications community!
UC3 New Year Series: The Merritt Digital Preservation Repository in 2025
At UC3, we’re dedicated to advancing the fields of digital curation, digital preservation, and open data practices. Over the years, we’ve built and supported a range of services and actively led and collaborated on initiatives to open scholarship. With this in mind, we’re kicking off a new series of blog posts to highlight our core areas of work and where we’re heading in 2025.
With the close of 2024 and beginning of 2025, the Merritt team is preparing for a new year of exciting projects and engagements with libraries and organizations across the UC system. We wrapped up 2024 by fully revising our Ingest queueing system to allow for more granular control over submissions processing, an effort which laid the groundwork for upcoming features, many of which we’ll discuss here. These include potential user-facing metrics, submission status and a new, easier to use manifest format for batch submissions.
Meanwhile, the team is always hard at work making the repository’s existing functionality more robust and future proof. We’ll also review some of these efforts and how they both provide reassurance to collection owners and improve users’ overall experience with the system.
Submission Status and Collection Reports
Implementing Merritt’s revamped queueing system was the most significant change to the way the repository ingests content that’s taken place since its inception. The new system establishes and allows for visibility into many more stages of the ingest process.
Every individual job now moves through these phases:
Internally, the Merritt team can monitor these steps through the repository’s administrative layer and intervene as necessary. For example, if one or more jobs in a batch fails, our team can assist by restarting a job or investigating what happened. Once a job is processing again, we can now also send additional notifications regarding the batch it belongs to.
While it’s possible for the team to view when a job or batch of jobs reaches any stage, Merritt currently does not provide this same insight to its users. We’ve already obtained preliminary feedback that such visibility would be helpful and are planning to gather additional input via an upcoming depositor tools survey regarding which stages are most useful and how to present them. In this vein, the survey will seek to capture information pertaining to your workflows for submitting content to the repository, and what new information and tools would make these more efficient for you. Our goal will be to identify trends in responses and focus on a key set of features to optimize Merritt’s usability.
Alongside visibility into a submission’s status, we would also like to provide additional information about the corresponding collection, post-submission. On every collection home page, we display specific metrics about the number of files, objects and object versions in the collection as well as storage space used. Given our recent work on object analysis and data visualization, we plan to surface additional data on the composition of a collection in its entirety. Our current thinking is to bubble up the MIME types of files, a date range that takes into account the oldest and newest objects in the collection, as well as the most recently updated object. A downloadable report with this data may also be an option, directly from the collection home. Again, stay tuned as we’ll be looking for your input on what’s most important to you in this case.
New Manifest Format
There are any number of ways to ingest content into Merritt – from single submissions through its UI, to API-based submissions and also use of several types of manifests that tell the system from where it should download a depositor’s content for processing.
In essence, a manifest is a list of file locations on the internet saved to a simple but proprietary format. Depending on the type of manifest, it may or may not contain object metadata. Although Merritt’s current range of manifest options provides a great deal of flexibility for structuring submissions, it can present a steep learning curve if a user’s goal is to deposit large batches of complex objects.
To help make working with manifests a more intuitive process, we’ve drafted a new manifest schema that records objects in YAML. Unlike current manifests, this single schema can be adapted to support definition of any object or batch of objects. For example, it allows for defining a batch of objects, where each object can have its own list of files and object metadata, all in one .yml file. Currently, this approach requires use of multiple manifests – one that lists a series of manifest files, and the other manifests to which it refers (a.k.a. a “manifest-of-manifests”). Each of these latter files records an object and its individual metadata. The new YAML schema should allow for more efficient definition of multiple objects in a single manifest, while also being more intuitive and easier to approach.
Available Services
Object Analysis
The Merritt team has endeavored to provide collection owners the means to obtain more insights into the composition of the content being preserved in the repository. More specifically, we’ve leveraged Amazon OpenSearch to record and categorize characteristics of both the file hierarchy in objects as well metadata associated with them. The Object Analysis process is one by which we gather this data from the objects in a specific collection upon request, and then surface the results of subsequent categorization and tests in an OpenSearch dashboard for review. We then walk through the dashboard with the collection owner and library staff to explore insights. For more information, have a look at the Object Analysis Reference or our presentation at the Library of Congress and let us know if you would like to explore your collections! Our goal is to provide you with the critical information needed for taking preservation actions that promote the longevity of your content.

Ingest Workspace
Last fall we brainstormed on how we could more effectively help library partners ingest their collections into Merritt while also minimizing their overhead associated with staging content. For example, if a collection owner’s digitization project results in files saved to hard drives, staging those files shouldn’t necessarily require they have on-premises storage and local IT staff who can administer it while staging and validation actions occur. Through use of a workspace our team has designed, it’s possible to assist with copying content to S3 and leverage a custom process (implemented via AWS Lambda) to automate the generation of submission manifests.

If you’re spinning up a digitization project in the near future which entails a digital preservation element, let us know!
What We’re Working On
As mentioned, we’re always working to make Merritt more robust, secure and easy to maintain for the long run. There are many more granular reasons for undertaking this work, but this year we’re keen to buckle down on our disaster recovery plans, ensure we’re making use of the latest AWS SDK version to interact with cloud storage at multiple service providers and also continuing to set up the building blocks for autoscaling Merritt’s microservices.
Disaster Recovery Plans
It goes without saying that any digital preservation service and its accompanying policies are inherently geared to prevent data loss. However, when truly unexpected events happen, the best thing we can do is strategize for the worst. In our case, because the content we steward lives entirely in the cloud, we need to be prepared for any of those services to become suddenly unavailable. Discussion in the larger community surrounding digital preservation in the cloud has continued, especially as organizations consider moving forward without a local, on-prem copy of their collections. Given Merritt already operates in this manner, it should be able to pivot and recognize either of its two online copies as its primary copy, while continuing to run fixity checks and replicate data to new storage services. Note the system’s third copy in Glacier is not a primary copy candidate due to the excessive costs associated with pulling data out of Glacier for replication. So while we already have the means to back up critical components such as Merritt’s databases, recreate microservice hosts in a new geographic region, and a well known approach to redefining collection configuration (i.e. primary vs. secondary object copies), we need a more efficient implementation to perform the latter reconfiguration on the fly. We intend to work on this storage management implementation in late 2025, detailing its operation not only as part of a disaster recovery plan, but also in our upcoming CoreTrustSeal renewal for 2026.
Talking to the Cloud
Although it doesn’t happen often (rewind to 2010 when the AWS SDK for Java 1.0 was introduced), major version updates to Amazon’s SDK that enables programmatic communication with S3 are inevitable. That’s why we’ve already spent considerable time testing use of v2 of the SDK for Java across all three of our cloud storage providers. So we’ll be ready Amazon ends support for v1 in December of 2025.
Autoscaling for Efficiency
As you may have gathered from some of our regular CDL INFO newsletter posts, a long term goal for our team is to enable certain Merritt microservices to autoscale. In other words, the number and size of submissions to the repository elements that are constantly in flux. Most days we see hundreds of small metadata updates process for e.g. eScholarship publications being preserved in the system. On other days, depositors may submit upwards of a terabyte a piece of new content while the service concurrently processes direct deposits whose updates stem from collections in Nuxeo. Given this variability, our consideration of the impact to the environment of excessive compute resources in the cloud, and compute and storage costs, Merritt should only be running as many servers as it needs anytime. Particularly, because we run every microservice in a high-availability fashion, we should be able to increase the amount of compute on days of heavy submissions, and more critically, reduce the number of hosts when minimal content is being ingested. Revamping our queueing process was a major requirement for autoscaling. With this complete, we (and all UC3 teams) now need to migrate into our own AWS account to further refine control over repository infrastructure. This next step will move us ever closer to fulfilling our goal to autoscale. We’ll continue to share more information on this in our regular posts going forward, so keep an eye out for the latest news!
In closing, we’re excited to work with our library partners throughout the coming year on both potential new features and by collaborating on new projects via recently introduced tools. Reach out to us anytime!
UC3 New Year Series: Looking Ahead through 2025 for the DMP Tool
At UC3, we’re dedicated to advancing the fields of digital curation, digital preservation, and open data practices. Over the years, we’ve built and supported a range of services and actively led and collaborated on initiatives to open scholarship. With this in mind, we’re kicking off a new series of blog posts to highlight our core areas of work and where we’re heading in 2025.
We’re gearing up for a big year over at the DMP Tool! Thousands of researchers and universities across the world use the DMP Tool to create data management plans (DMPs) and keep up with funder requirements and best practices. As we kick off 2025, we wanted to share some of our major focus areas to improve the application and introduce powerful new capabilities. We always want to be responsive to evolving community needs and policies, so these plans could change if needed.
The DMP Tool in 2025
Our primary goal for the year is to launch the rebuild of the DMP Tool application. You can read more detail about this work in this blog post, but it will include the current functionality of the tool plus much more, still in a free, easy to use website. The plan is still to release this by the end of 2025, likely in the later months (no exact date yet). We’re making good progress towards a usable prototype of core functionality, like creating an account and making a template with basic question types.
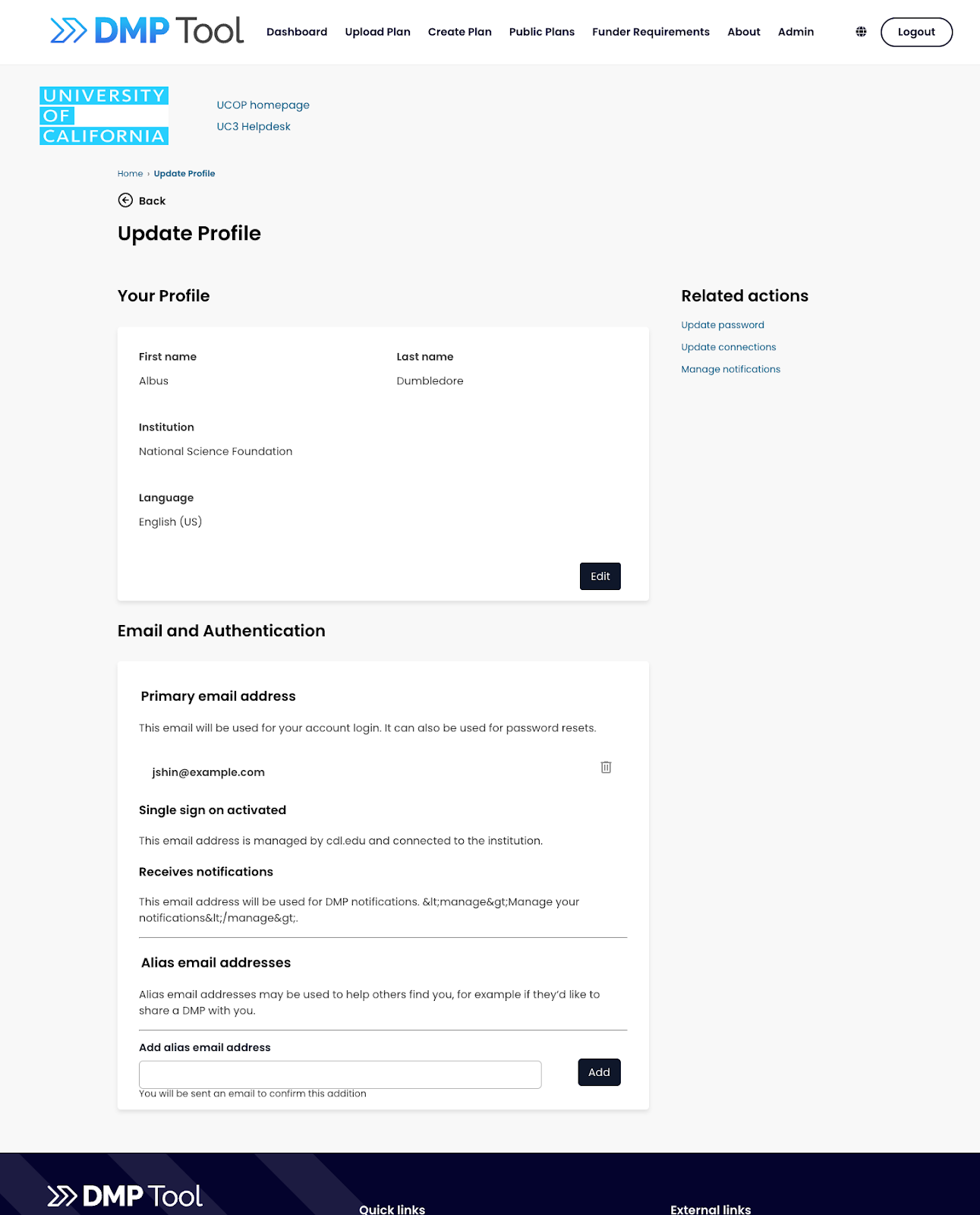
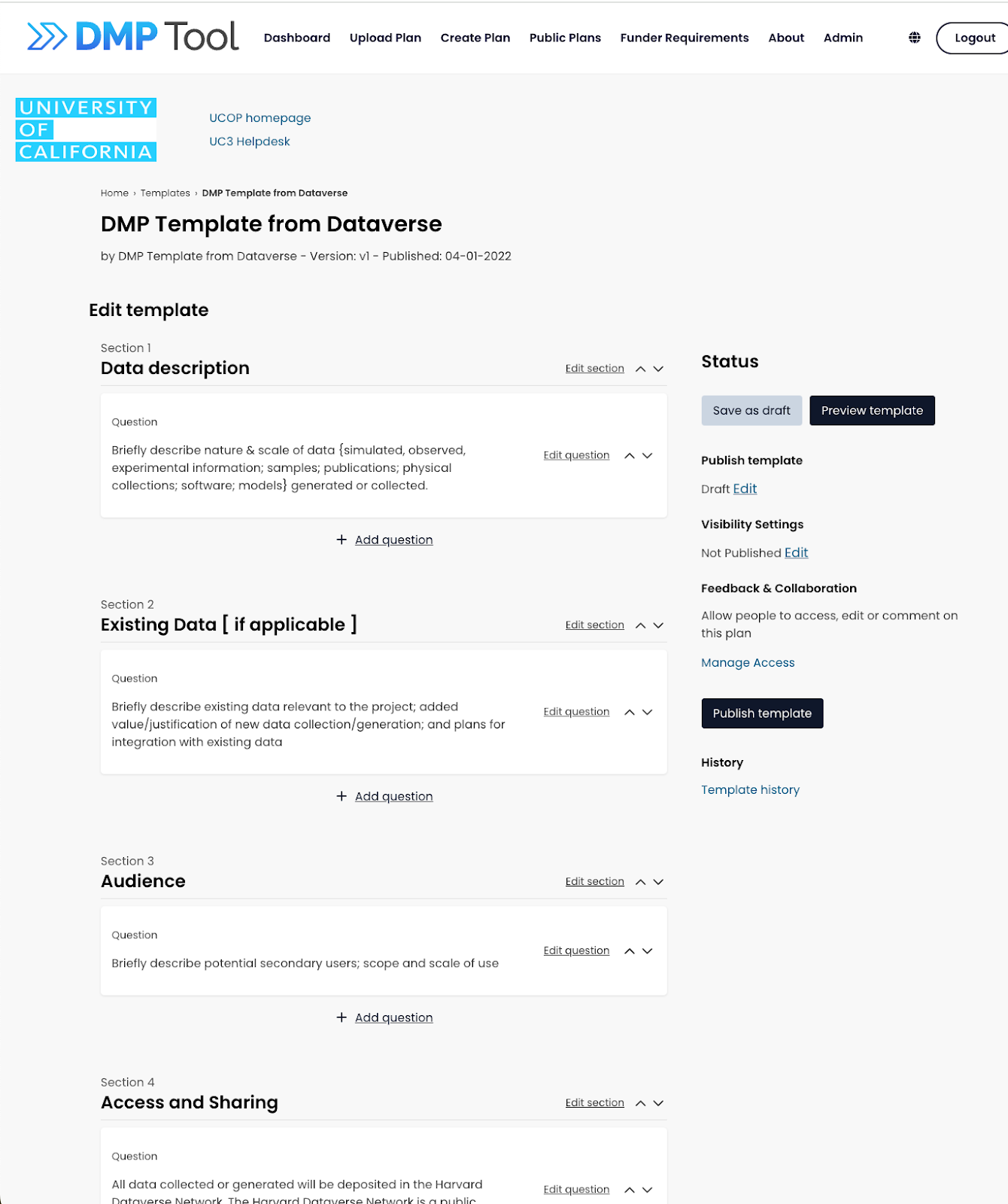
Another common request is to offer more functionality within our API. For example, people can already read registered DMPs through the API, but many librarians want to be able to access draft DMPs to integrate a feedback flow on their own university systems. As part of our rebuild, we are moving to a system that is going to use the same API on the website as the one available to external partners (GraphQL for those interested). This will allow almost any functionality on the website to be available through the API. This should be released at the same time as the new tool, with documentation and training to come. Get your integration ideas ready!
Finally, we are continuing to work on our related works matching, tracking down published outputs and connecting them to a registered DMP. This is part of an overall effort to make DMPs more valuable throughout the lifecycle of a project, not just at the grant submission stage, and to reduce burden on researchers, librarians, and funders to find related works. It’s too early to tell when this will be released publicly on the website, but likely will come some time after the rebuild launch.
AI Exploration
While most of our focus will be on the above projects, we are in the early stages of exploring topics for future development of the DMP Tool. One big area is in the use of generative AI to assist in reviewing or writing data management plans. We’ve heard interest from both researchers and librarians in using AI to help construct plans. People sometimes write their DMP the night before a grant is due and request feedback without enough time for librarians to provide it. AI could help review these plans, if trained on relevant policy, to give immediate feedback when there’s not enough time for human review.
We’re also interested in exploring the possibility of an AI assistant to help write a DMP. We know many people are more comfortable answering a series of multiple choice questions than they are in crafting a narrative, and it’s possible we could help turn that structured data into the narrative format that funders require, making it easier for researchers to write a plan and keeping the structured data for machine actionability. Another option is an AI chatbot within the tool that can help provide our best practice guidance in a more interactive format. It will be important for us to balance taking some of the writing burden off of researchers while making sure that they are still the one responsible for the content within it.
These ideas are in early phases – it’s something we’ll be exploring but not releasing this year – however we’re excited about their potential to make DMPs easier to write.
Community Engagement
While it may seem we’ll be heads down working on these big projects, we want to make sure we’re communicating and participating in the wider community more than ever. As we get towards a workable prototype of the new tool, we’ll be running more user research sessions. The initial sessions, reviewed here, offered a lot of valuable insight that shaped the current designs, and we know once people get their hands on the new tool they’ll have more feedback. If you haven’t already, sign up here to be on the list for future invites.
We also want to be more transparent with the community about our operations and goals. We’ve started putting together documents within our team about our Mission and Vision for the DMP Tool, which we’ll be sharing with everyone shortly. Over 2025, we want to continue to work on artifacts like those we can share regularly so that you all know what our priorities are. One goal is to create a living will, recommended by the Principles of Open Scholarly Infrastructure, outlining how we’d handle the potential winddown of CDL managing the DMP Tool. This is a sensitive area because we have no plans to wind down the tool, and don’t want to give the impression that we will! But it’s important for trust and transparency for us to have a plan in place if things change, as we know people care about the tool and their data within it.
Finally, we’ll be wrapping up our pilot project with ARL this year, where we had 10 institutions pilot implementation of machine-actionable DMPs at their university. We’ve seen prototypes and mockups for integrations related to resource allocation, interdepartmental communication, security policies, AI-review, and so much more. We’ve brought on Clare Dean to help us create resources and toolkits, disseminate the findings, and host a series of webinars about what we’ve learned to help others implement at their own universities. We’ll be presenting talks on the DMP Tool at IDCC25 in February, RDAP in March, and we plan to submit for other conferences throughout the year, including IDW/RDA, to share what we’ve learned with others. We hope to continue working with DMP-related groups in RDA to ensure our work is compatible with others in the space, and we’re following best practices for API development.
We hope you’re as excited for these projects as we are! We’re a small team but we work with many amazing partners that help us achieve ambitious goals. Keep an eye on this space for more to come.