(index page)
Reflections on Persistence: A Farewell to CDL
Today marks the conclusion of my 5+ year chapter working with the UC3 team at CDL and collaborators across the the world to build, lead, and support infrastructure and initiatives for a more open, connected, and sustainable research ecosystem. This chapter comes to a close as I embark on a new one: joining DataCite as Director of Product. At DataCite, as with UC3, my goals and activities will continue to focus on driving innovative collaborations to support libraries and research communities worldwide and enable greater access to knowledge.
CDL has a long history of leadership and innovation with persistent identifiers. This is where ARKs were developed, where N2T was built, where EZID paved a new approach to centralized PID-agnostic services, where DMP-IDs were launched, where global collaborations like DataCite and ROR have roots, and much more. We have been in the unique position at CDL to both develop and maintain actual infrastructure and to lead and participate in community initiatives to drive adoption and best practices. UC3’s identifiers portfolio has played – and will continue to play – a strategic role in enabling the University of California’s goals around open scholarship. Being part of these developments over the past 5+ years has been an honor and a privilege.
The world of persistent identifiers is very different today in January 2024 than it was when I stepped into my role in 2018. The past five years have seen an explosion of conversations about PIDs, adoption of PIDs, and the emergence of entirely brand-new PIDs. PIDs have moved from niche corners of the research landscape to be front and center in institutional research policies and federal government guidance.
The work is certainly not done and the many promises of PIDs need to continue to be explored and fully realized. But we are undoubtedly in a different and better place than we were 5 years ago.
PIDs emerge and are often used in the context of technical infrastructure. However, one of the biggest lessons I have learned in my time at UC3 is that PIDs depend on people. Many of the developments we have seen over the past five years have been the result of people and communities coming together to make something better or develop a new solution. The organizations and initiatives running and operating different PID services and systems depend on this kind of active engagement to ensure we are building sustainable, scalable, solutions that address specific challenges, build on existing work, and bring wide-ranging benefits.
By the same token, an identifier’s persistence is only as strong as the communities behind it, and this can become challenging as people switch roles, as organizations evolve or shut down, as technology changes, and as shiny new projects emerge. Persistence is a problem often discussed from a technical standpoint. But the human side is just as challenging, and long-term responsibility for any infrastructure is not something to be taken lightly.
Persistence must be bigger than and not depend upon a single person. To that end, it is worth noting that this work will continue after I leave, and the portfolio is in expert hands within the UC3 team. As this chapter comes to a close, I would like to express my gratitude to my colleagues at UC3 and CDL, to the rich network of librarians across UC, and to the wider PID community for their collaborations and support over the years, and I look forward to a new journey ahead together
Identifier services at CDL: Connecting our communities
Last week, more than 1100 people registered to attend PIDapalooza21, a 24-hour-long virtual event celebrating persistent identifiers and the communities that use them. Held online for the first time due to the COVID-19 pandemic, PIDapalooza21 was able to attract a much larger audience than any of the four previous PIDapaloozas. But even by virtual event standards, 1100 people is still a lot! Does this mean that persistent identifiers are now mainstream? And if so, what does this mean for the identifier services and initiatives that we lead at California Digital Library?
Background: Identifiers at CDL
The identifiers portfolio at CDL encompasses technical infrastructure, such as the EZID service, and cross-organization collaborations, such as CDL’s leadership role in the Research Organization Registry (ROR) as well as PIDapalooza. In the spirit of CDL’s broader mission and vision, the identifiers portfolio aims to enable the discoverability, citability, and long-term stewardship of UC data, research outputs, publications, special collections, and archives. We do this by supporting identifier use and adoption across the UC campuses, enriching CDL’s core infrastructure for publishing, data management, and preservation, and contributing to global identifier initiatives that can help to further amplify UC scholarship.
Identifiers in open research infrastructure
While persistent identifiers themselves are associated with fixity and stability, the landscape in which they are situated is constantly shifting. Research infrastructure is becoming more complex and more connected. Institutions, publishers, funders, and policymakers are under more pressure to track and quantify research activities. Infrastructure providers face growing costs and competition.
Identifiers can help us navigate this landscape and address these challenges. But persistent identifiers alone are not the solution.
A DOI string for a dataset doesn’t tell us anything about what data is captured, or who created it, where that researcher is affiliated, or which funders supported the research project. But if the metadata registered with the DOI includes these details, the identifier becomes meaningful and powerful.
While more people are paying attention to identifiers these days—as evidenced by the record attendance at PIDapalooza—there is still a need to drive home the point that the identifiers themselves are not the goal; it’s about what the identifiers can do. In order to fulfill the true promise of identifiers, we need to be able to connect them through open data, open metadata, and open infrastructure. And we need communities to understand how to do this and why it is important.
What does this mean for EZID?
A year ago, we reflected on EZID’s evolution as the service has pivoted from its original foundations to pursue a new vision for the future of identifier services at CDL. In the past year, work on EZID has been focused on modernizing and strengthening its core infrastructure so that we can achieve this vision. Some highlights include:
- We completed a migration to Linux2 and are working on upgrading the EZID codebase.
- We streamlined core functionality for shoulder handling and identifier minting to remove dependencies on external systems.
- We added support for the latest versions of the DataCite and Crossref DOI metadata schemas so that users can include richer metadata for their DOIs and also register DOIs for new content types such as preprints.
As 2021 gets underway, work on EZID and across the identifiers portfolio in general will involve building on these infrastructure efforts to harness the power of PIDs. Our goals fall into three main areas:
- Enriching our metadata: Encourage and enable better DOI metadata: Help users take advantage of the DataCite and Crossref schemas by providing more descriptive information to support tracking and discovery.
- Opening and connecting our infrastructure: Help users understand the power of connecting research through identifiers in open infrastructure like the DMPHub, Make Data Count, and DataCite Commons.
- Promoting best practices and policies: Provide recommendations and guidance for research stakeholders working with identifiers, such as those summarized in the recent report, Implementing Effective Practices for Data: Recommendations for Collaborative Research Support.
Identifiers are a key aspect of our collective research infrastructure and it is an exciting time to be working on how to best leverage them to connect our communities.
Party with PIDapalooza (virtually) in 2021
PIDapalooza is going online in 2021!
We wish we could all be together in person for the fifth (!) festival of persistent identifiers, but we’re excited to bring the world’s largest—and longest—virtual PID party directly to your desk, your couch, your balcony—really, anywhere there’s a strong WiFi signal.

PIDapalooza 2021 will be a 24-hour nonstop PID party happening around the world. PIDapalooza has never been a regular conference and this one will be no different!
The party starts on January 27 at 14:30 UTC (see the time in your location here). Sessions will take place over the course of the following 24 hours. That’s right: we’re partying all night long and no matter your time zone, you’ll be able to join in.
Propose a session…and visit PIDapalooza.org for more details to about the program, the structure, and how to participate.
In the meantime:
- Mark your calendars!
- Think about a session to propose, any keynotes or program topics to suggest, and any co-located meetings you might want to hold that week. We’ll send out a call for proposals toward the end of September
- Add your favorite jam to the 2021 playlist!
- Keep on rockin’ the PIDs!
PIDapalooza 2021 is brought to you by the following PID groupies:
California Digital Library, Crossref, DataCite, NISO (welcome to our newest groupie!), and ORCID
For more information, visit the PIDapalooza website and follow PIDapalooza on Twitter.
PIDapalooza 2020: Highlights from the Fourth Festival of PIDs
Last month, PIDapalooza rocked the world again! The fourth festival of persistent identifiers, which took place in Lisbon, featured a Portuguese classical guitarist, a Japanese nail artist, an interpretive dance about the scientific process, several uses of beach balls, silly hats and bells, the latest version of the fabulous PIDapalooza playlist and, of course, the lighting of the eternal flame!
There it is, the eternal flame of persistence is turned on thanks to its supporters 🔥 #PIDapalooza2020 @ORCID_Org @datacite @CrossrefOrg @CalDigLib pic.twitter.com/1ZnaqbAZYe
— Mohammad Hosseini (@mhmd_hosseini) January 29, 2020
The festival lineup in Lisbon was impressive, with more than 40 different sessions from expert speakers who shared their PID successes and challenges, presented their visions for PID connections and PID communities, and introduced new PIDs on the block, all while discussing these serious topics in a range of interactive and engaging formats.
Not to mention the festival headliners: three inspiring keynote speakers…
First up was Maria Fernanda Rollo, Associate Professor at the Universidade Nova de Lisboa. Her talk, Towards the Circular Science: PIDs for a New Generation of Knowledge Creation and Management Paradigm in Portugal — from Vision to Reality, focused on her experience as Portugal’s former Secretary of State for Science, Technology, and Higher Education. As the person responsible for developing their national strategy for open science, Maria’s priority was more science, less bureaucracy — not as simple as it sounds! Democratization, efficiency, and transparency were key to the Portuguese PID policy, which included developing Estudante IDs for students and Ciencia IDs for everyone involved in science.
The second keynote, The Science Ecosystem and Open Science: A Multi-Legged Stool, was delivered by Beth Plale, program officer at the US National Science Foundation, working on open science, and a Professor in the Department of Intelligent Systems Engineering at Indiana University – Bloomington. Like Maria, Beth highlighted both the benefits and the challenges of open science, but her focus was primarily on data. She encouraged us to think about treating different kinds of digital content differently — for example, suggesting that not all data needs to be kept forever. And she noted that although “there’s a [PID] brain trust in this room,” most people don’t understand and/or care about identifiers; there’s a lot of work to be done on that front!
Last, but very definitely not least, was the closing keynote, Kathryn Kaiser, Assistant Professor and Scientist in the Office of Energetics at the University of Alabama – Birmingham. Her talk was entitled Dancing with the Scientists: The Costs of Piddling with Science without PIDs. In a festival-inspired mix of music, animation, and interpretive dance (yes, featuring a unicorn-themed beach ball), not to mention some memorable analogies — cheese as a metaphor for metadata, fishing as a metaphor for systematic reviews — Kathryn shared her pain, her struggles, her data, and her hopes as a researcher doing systematic review work in nutrition and obesity topics and relying on quality data infrastructure.
We are definitely all awake and energized after this fun start to @KatKaiserPhD’s keynote #PIDapalooza2020 😀 pic.twitter.com/SFw6A4nnQh
— PIDapalooza (@pidapalooza) January 30, 2020
#PIDapalooza2020 was the largest-ever gathering in the festival’s four years, with about 175 participants from around the globe, many attending for the first time.
And that’s a wrap! Farewell #PIDapalooza2020 & farewell Lisbon! Thanks to everyone for being such a great crowd – see you again for #PIDapalooza2021 in ….??? (But not Wyoming. Sorry Wyoming.) pic.twitter.com/0NIAbaLvCD
— PIDapalooza (@pidapalooza) January 30, 2020
When we asked festival attendees (*in a very scientific poll*) whether we had rocked their world this year, the answer was a resounding “Hell, yeah!”
We also asked you if #PIDapalooza2020 rocked your world. And yeah, hell yeah it did (apart from a handful of grumpy people)! pic.twitter.com/JAdcMu400l
— PIDapalooza (@pidapalooza) January 30, 2020
It is clear from attendee feedback that PIDapalooza is truly a unique event, bringing together a specialized community to discuss important topics in a friendly and inclusive setting. Some highlights from the 2020 festival in their words:
It was an incredibly positive and productive event! I appreciated the ability to connect with the leading experts in the PID community. It is a testament to the meeting that it draws a braintrust like this.
[I liked] That all keynote speakers were women! But also the rather “informal” approach (taking yourself not too seriously while taking the work seriously).
The range of parallel talks means that you can really tailor your conference experience. It can be totally different from the journey your colleagues and friends experience, and you can share what you have learned over delicious canapés in a rainy city!
There’s a wonderful community feel – everyone is interested in sharing, learning, and having conversations during breaks. It’s amazing to have the leading PID folks in one place!
This is the best meeting to attend for the work I do.
It will soon be time to start thinking about the next PIDapalooza — the fifth! We’re already thinking about using that important anniversary as an opportunity to experiment — with the format, the location, or both — as well as continuing to build on all the things people love about the event.
In the meantime, whether or not you were in Lisbon yourself, you can experience or revisit #PIDapalooza2020 on Twitter and through the presentations available on the PIDapalooza 2020 community page on Zenodo.
Post contributed by the PIDapalooza 2020 organizing committee: Ana Afonso (FCT), Helena Cousijn (DataCite), Maria Gould (CDL), Stephanie Harley (ORCID), Ginny Hendricks and Maria Sullivan (Crossref). Special thanks to Alice Meadows (NISO) for editorial support.
Persistent Identifier Services at CDL: A Rich Tapestry
EZID is one strand in a larger tapestry of persistent identifier activity at CDL. These activities, at their core, are focused on how and where persistent identifiers can help enrich and connect the scholarly outputs and cultural heritage materials of the University of California system. Persistent identifiers in this sense both drive and support CDL’s underlying mission to “provide[s] transformative digital library services, grounded in campus partnerships and extended through external collaborations, that amplify the impact of the libraries, scholarship, and resources of the University of California.”
The past year was a transitional one for EZID in particular and for CDL’s identifier services portfolio in general. In the first half of 2019, we completed a multi-year process to rescope EZID’s DOI services to focus exclusively on UC users. We worked to support non-UC users of our DOI services in setting up direct memberships with other providers through memberships with Crossref and DataCite. We also welcomed Rushiraj Nenuji to the development team as we said farewell to EZID’s long-time developer and original architect Greg Janée.
Last year, in the midst of these transitions, we posed the following question:
Rather than thinking about EZID solely as a tool or a service, we want to situate it instead as one layer of a deep and broad persistent identifier portfolio at CDL. EZID is a great tool for creating and managing DOIs and ARKs—what else could it do? And how might it also support infrastructure, training, and outreach for a more networked and interoperable scholarly communication ecosystem through the use and coordination of persistent identifiers?
Now, as we kick off the new year, we wanted to provide a brief update on what this persistent identifier services portfolio looks like, and how it will continue to evolve in the months ahead.
EZID remains involved in the day-to-day business of supporting DOI and ARK services for UC campuses as well as ARK services for non-UC EZID members. EZID development work is currently focused on strengthening and upgrading the application for long-term robustness and stability, and reconfiguring the platform to minimize dependencies on external systems. Future development work in the coming months will be geared toward optimizing the EZID user interface and adding more support for different metadata schemas.
From the portfolio perspective, we are working on a number of initiatives to encourage and enable the adoption and use of persistent identifiers across the UCs and beyond. A few examples:
We work closely with CDL’s eScholarship Publishing team to help UC journals obtain Crossref DOIs. An integration between eScholarship and EZID assigns DOIs automatically to eScholarship journal articles and sends the metadata to Crossref. These articles are then available to indexes, libraries, and other third parties, enhancing journals’ exposure and increasing the discoverability of their Open Access content. This service supports about 20 journals and our teams will expand to more publications in the year ahead. Two related efforts concern greater adoption of ARK identifiers for special collections objects (UCSF’s Industry Documents Library is one recent project), and DataCite DOIs for UC data repositories.
Organization identifiers are growing in visibility across the scholarly infrastructure landscape with the launch of the Research Organization Registry (ROR), of which CDL is a founding partner. The ROR registry now includes unique IDs for approximately 97,000 organizations, and these IDs are being supported in both DataCite and Crossref metadata. A number of platforms are integrating or looking to integrate ROR into their systems wherever affiliations are collected. The new Dryad platform was the first to pilot this type of ROR integration, and Dryad now has clean and consistent affiliation data for all of its datasets. With additional integrations expected in the new year, it will become increasingly easier for libraries and research administrators to track and analyze their institutions’ scholarly outputs.
Engaging with the broader PID community is another important aspect of our ongoing work. CDL is a member of the ORCID US Community, joining other institutions around the country in championing adoption and use of ORCID identifiers by UC researchers. We are also a founding sponsor of PIDapalooza, the festival of persistent identifiers now approaching its fourth year. We are collaborating within and beyond the UC in persistent identifier training and outreach, including providing guidance on identifiers for UC librarians, and organizing global workshops for stakeholders and practitioners.
All of these efforts showcase how persistent identifier services capture the spirit of the CDL’s vision as a “catalyst for deeply collaborative solutions providing a rich, intuitive and seamless environment for publishing, sharing and preserving our scholars’ increasingly diverse outputs.”
We are looking forward to the year ahead! As always, get in touch with your ideas and questions.
We’re Having a (PID) Party – And You’re Invited!
PIDapalooza 2020 is just around the corner (January 29-30, Lisbon, Portugal) — and it’s going to be fun! We have a great venue, the fabulous Belem Cultural Center, and a great lineup:
- On the main stage — three amazing keynotes: Maria Fernanda Rollo (NOVA FSCH), Beth Plale (NSF), and Kathryn Kaiser (University of Alabama, Birmingham). Plus a surprise local guest to help celebrate the start of the event!
- Throughout the event — more than 35 fast-paced sessions on a wide range of PID themes, from Achieving Persistence through Sustainability to PID Success Stories, and beyond
- Five PID Party sessions — 30-60 minutes of PID fun and games galore, led by the likes of ORCID, NISO, and TIB Hannover
- Our first-ever lightning talks — make sure you sign up on day 1 for your slot in this new one-hour session of rapid-fire, five-minute talks on the PID topic of your choice
- Not one, but two unmissable social events — a pay-your-own-way pre-meeting get-together at the TimeOut Market Lisbon on January 28, and the official PIDapalooza reception at 5:30pm on January 29 (venue to be announced soon).
- Plus all the usual fun you’ve come to expect from your favorite PID festival — the lighting of the eternal flame, your very own PIDapalooza T-shirt, the pub quiz, the wrap-up session, and more!
You can see the full lineup here, and tickets are now on sale (a bargain at just US$150!). Half of the available places are already filled (as of early December) — so get yours now!
Whether you’ll be attending PIDapalooza for the first or the fourth time — or if you’ve never attended — we’d also love to hear your thoughts about the event, so please take a few minutes to complete this short survey. We’ll share the results at PIDapalooza 2020, and on our blogs.
Thanks — and see you in January!
Your friendly neighborhood Planning Committee
Ana Afonso (FCT), Helena Cousijn (DataCite), Maria Gould (CDL), Stephanie Harley (ORCID), Ginny Hendricks and Maria Sullivan (Crossref)
Keep on ROR-ing: A Research Organization Registry Update
The Research Organization Registry (ROR) has had a big year! As CDL is a key partner in the ROR initiative, we are posting some updates here about what has been happening with ROR and where we’re going next.
The first prototype of the ROR registry launched in January and now includes unique IDs and metadata records for nearly 100,000 organizations. The registry’s launch marked the culmination of several years of planning and collaboration by numerous organizations and stakeholders from across the scholarly communications landscape to establish a guiding vision and a core set of requirements for open infrastructure for research organization IDs and metadata.
ROR emerged to fill a crucial gap in scholarly infrastructure: while we already had an open network of identifiers for research outputs (DOIs for publications and data) and research contributors (ORCID IDs), open identifiers for research organizations were a missing piece. With ROR we now have the power and the ability to connect and leverage all of these identifiers to enable better discovery and tracking of research outputs across institutions and funding bodies.
In addition to the registry itself, ROR offers open tools for interacting with ROR data and implementing ROR IDs, including a front-end search interface, an open API, a reconciler that works with OpenRefine to clean up messy lists of affiliations, affiliation matching functionality to connect free-text affiliation strings to ROR IDs, and a public data dump. All of the ROR code is available on Github. As we grow the registry, we will be building curation tools for maintaining ROR records over time, establishing a community curation board, and developing more support for system integrations and for usage of registry data.
ROR IDs can be captured now in systems and platforms where researcher affiliations are collected, and supported in Crossref and DataCite metadata. A number of ROR integrations are active or in progress, spanning data repositories, manuscript tracking systems, grant application systems, institutional repositories, and others. One of these early implementations—a simple affiliation lookup in Dryad’s data publishing platform that collects clean and consistent affiliation data for each dataset submitted—is described in this blog post.
ROR is run as a community collaboration and led by academic and nonprofit organizations with deep expertise in scholarly communication and open infrastructure initiatives. All of ROR’s work so far has been completed through in-kind donations from its steering organizations. We also have supporters and advisors from across industries and around the world.
In the coming years, we want to further develop ROR to enable greater adoption and downstream uses. Our organizations are committed to ROR for the long-term but we can’t move forward without additional community support. We have launched a fundraising campaign in order to be able to scale up our operations, hire dedicated staff, and develop and deliver new features, with a plan to launch a paid service tier in 2022 to recover costs while keeping the registry’s data open and free for all.
The ROR campaign’s first fundraising target is $75,000 by the end of 2019, and we have raised $36,000 so far, bringing us nearly halfway to our year-end goal. We are grateful to the following supporters for getting the campaign off to a strong start:
- Altum
- American Physical Society
- American Psychological Association
- Association for Computing Machinery
- Center for Science and Technology Studies (CWTS), Leiden University
- Curtin University
- Dryad
- eLife
- German National Library of Science and Technology (TIB)
ROR’s growing community of supporters speaks to the importance of building and sustaining open infrastructure for scholarly communications.
Steve Pinchotti, CEO of Altum—which has integrated ROR IDs into 26,000 institution profiles in its ProposalCentral grants platform—stated:
“ROR is a critical component of a connected research data landscape. As a software company focused on the advancement of research, Altum recognizes our responsibility to financially support and sustain the key research infrastructure initiatives like ORCID and ROR that enable open science and open global identifiers for research outputs, research contributors, and research institutions.”
Melissa Harrison, Head of Production Operations at eLife, adds:
“The distribution of high-quality metadata using various persistent identifiers is a great tool for advancing connections and the interlinking of scholarly content with other aspects of the ecosystem. We are delighted to support this community-led initiative for an open persistent identifier for research organizations to complement those we at eLife already use for content, peer review, data, people and funding.”
As we approach the end of the year, we are calling on our community to help ensure we will reach our goal. Contributions in any amount are welcome, and will go directly to support the registry’s growth and development. To start your contribution, email donate@ror.org to make a pledge and request an invoice. There are other ways to contribute as well—by spreading the word about the campaign, by implementing and adopting ROR IDs, and by telling others why open scholarly communications infrastructure matters to you.
Thank you for supporting ROR!
We’ll be rocking your world again at PIDapalooza 2020
![]()
The official countdown to PIDapalooza 2020 begins here! It’s 162 days to go till our flame-lighting opening ceremony at the fabulous Belém Cultural Center in Lisbon, Portugal. Your friendly neighborhood PIDapalooza Planning Committee—Helena Cousijn (DataCite), Maria Gould (CDL), Stephanie Harley (ORCID), Ginny Hendricks (Crossref), and Alice Meadows (ORCID)—are already hard at work making sure it’s the best one so far!
We have a shiny new website, with loads more information than before, including Spotify playlists (please add your PID songs to the 2020 one, an Instagram photo gallery, and of course registration information. Look out for updates there and on Twitter.
And, led by Helena, the Program Committee is starting its search for sessions that meet PIDapalooza’s goals of being PID-focused, fun, informative, and interactive. If you’ve a PID story to share, a PID practice to recommend, or a PID technology to launch, the Committee wants to hear from you. Please send them your ideas, using this form, by September 27. We aim to finalize the program by late October/early November.
Don’t forget to tie your proposal into one of the six festival themes:
Theme 1: Putting Principles into Practice
FAIR, Plan S, the 4 Cs; principles are everywhere. Do you have examples of how PIDs helped you put principles into practice? We’d love to hear your story!
Theme 2: PID Communities
We believe PIDs don’t work without community around them. We would like to hear from you about best practice among PID communities so we can learn from each other and spread the word even further!
Theme 3: PID Success Stories
We already know PIDs are great, but which strategies worked? Share your victories! Which strategies failed? Let’s turn these into success stories together!
Theme 4: Achieving Persistence through Sustainability
Persistence is a key part of PIDs, but there can’t be persistence without sustainability. Do you want to share how you sustain your PIDs or how PIDs help you with sustainability?
Theme 6: PID Party!
You don’t just learn about PIDs through Powerpoints. What about games? Interpretive dance? Get creative and let us know what kind of activity you’d like to organize at PIDapalooza this year!
PIDapalooza: the essentials
What? PIDapalooza 2020 – the open festival of persistent identifiers
When? 29-30 January 2020 (kickoff party the evening of January 28)
Where? Belém Cultural Center, Lisbon, Portugal (map)
Why? To think, talk, live persistent identifiers for two whole days with your fellow PID people, experts, and newcomers alike!
We hope you’re as excited about PIDapalooza 2020 as we are and we look forward to seeing you in Lisbon.
Cross-posted from the Crossref, DataCite, and ORCID blogs
ROR-ing Together: Implementing Organization IDs in Dryad
Co-authored by Maria Gould and Daniella Lowenberg and cross-posted from the ROR blog
How many datasets have been published in Dryad from researchers at the University of California? This question is surprisingly complicated. A short answer might be, we don’t know! A better answer could be, coming soon – stay tuned!
And a more complete and detailed answer might go something like this:
It’s not easy to determine how many datasets in Dryad are affiliated with the University of California – or any other institution, for that matter. This is the result of two main factors: (1) Dryad historically did not collect affiliation information from authors submitting datasets; and (2) even if Dryad had collected this information, it likely would have done so in a free-text field that allowed authors to write their affiliation in any number of ways (think “UC Berkeley,” “University of California-Berkeley,” or “Berkeley,” for example). Why? Because until recently, the scholarly research and publishing community did not have an easy and open option to rely on a standard set of affiliation names and related IDs to identify and disambiguate institutions.
This changed a few months ago with the launch of ROR – the Research Organization Registry. ROR is a community-led project to develop an open, sustainable, usable, and unique identifier for every research organization in the world. The ROR MVR (minimum viable registry) launched in January 2019 and began assigning unique ROR IDs to more than 91,000 organizations.
At its core, ROR is focused on filling a very specific and crucially important gap in scholarly research and publishing infrastructure: information about the organizations affiliated with researchers and research outputs. The rise of DOIs to identify datasets and publications and ORCID IDs to identify researchers and contributors has facilitated more efficient discovery and tracking of research outputs. But without being able to identify where these outputs and authors are affiliated, this discovery and tracking can only go so far. At best, an immense amount of additional and manual work is involved in extracting this information to fill the gap. At worst? The gap never gets filled in. With ROR IDs, the idea is that both of these scenarios no longer happen. ROR is intended for use by the research community, for the purposes of increasing the use of organization identifiers in the community and enabling connections between organization records in various systems.
ROR and Dryad joined forces this spring to tackle two different yet related challenges. Following the launch of the MVR, ROR was interested in finding a partner to pilot a simple yet effective implementation of the ROR API. Dryad was interested in implementing a solution to the problem of missing affiliation data. As a longstanding community partner in data publishing and open infrastructure projects, the Dryad team was eager to be an early adopter of ROR and blaze the trail toward wider implementation and collection of ROR IDs across multiple systems and platforms.
Dryad’s developers working on the new Dryad platform (launching later this summer) quickly got to work creating an affiliation field in the dataset submission form that calls the ROR API. When an author starts typing an affiliation, the field lookup searches for a matching name in ROR and shows the author a dropdown list of possible matches to choose from.
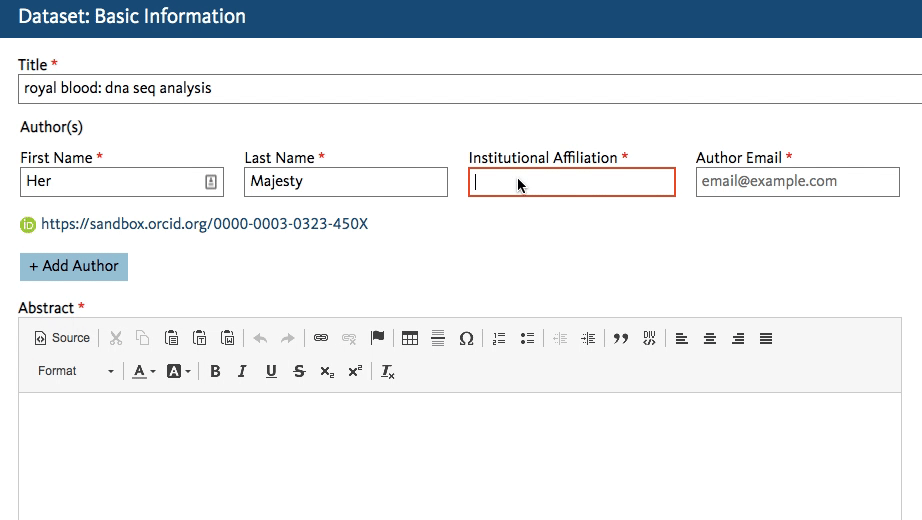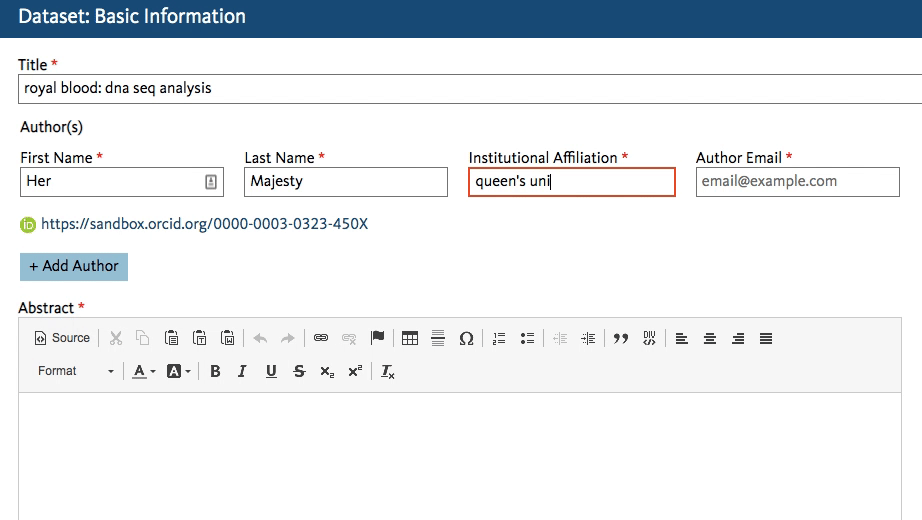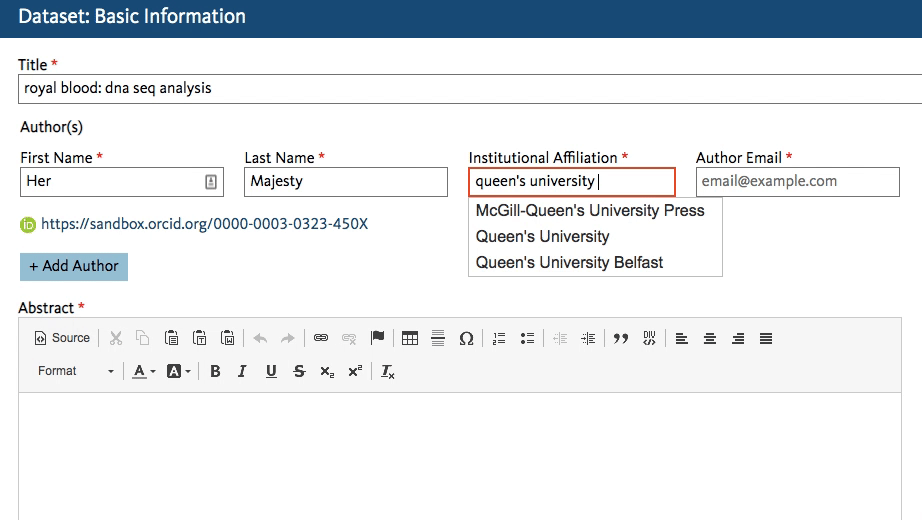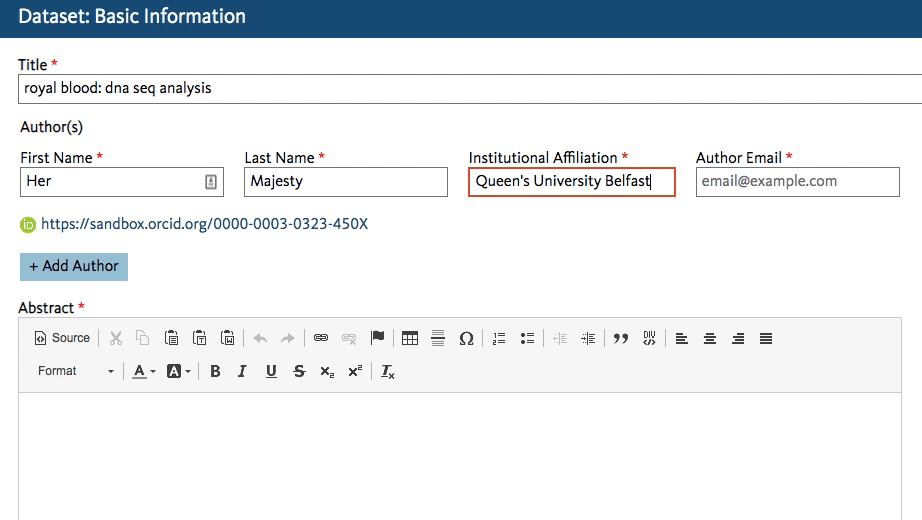
This will work regardless of whether the author starts entering a known abbreviation or the full name of the organization, as shown below.
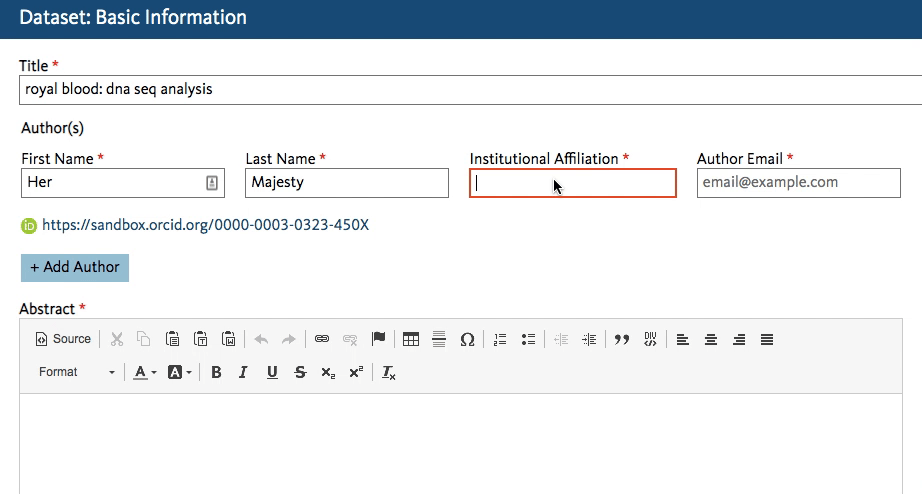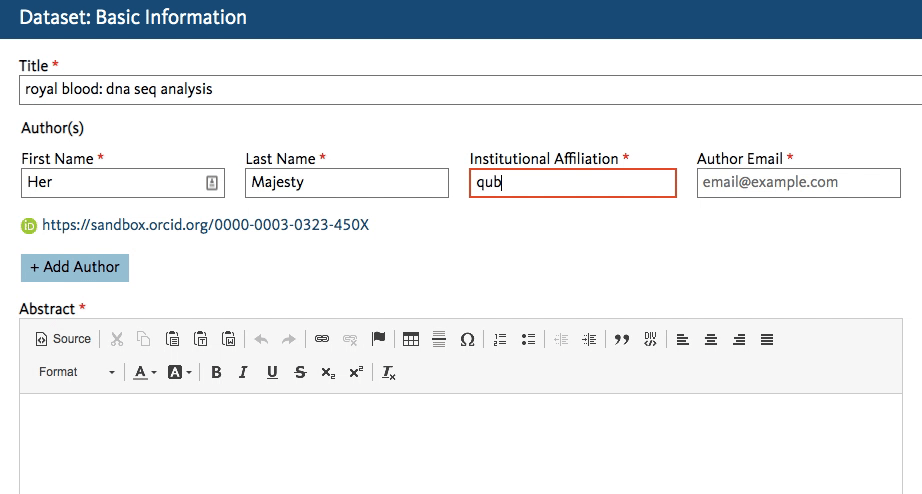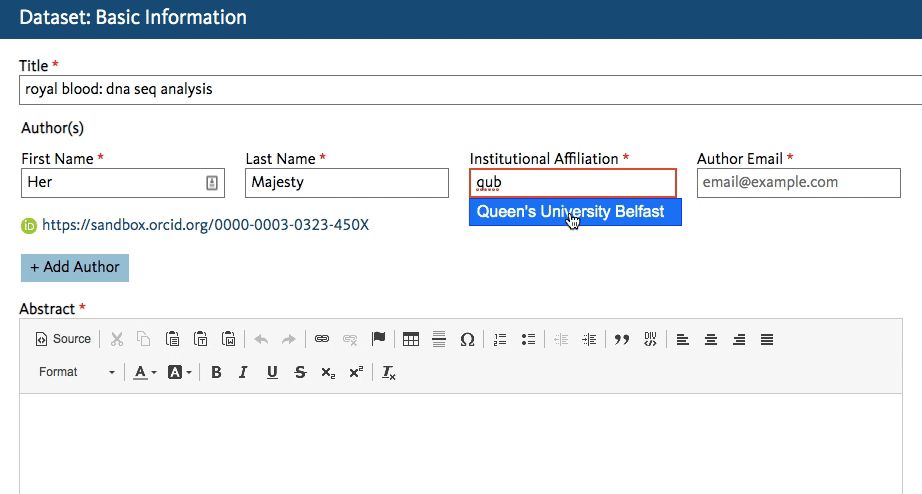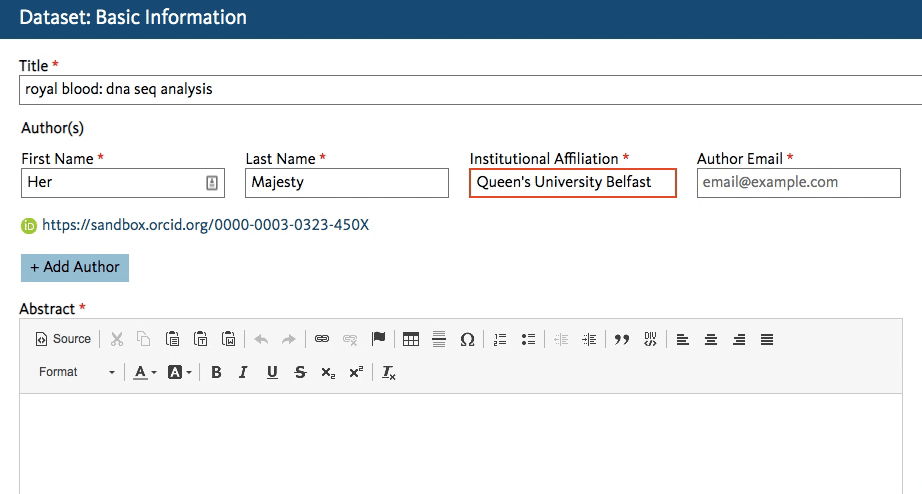
The author chooses the match and proceeds with the submission. The ROR ID is stored in the database – the author doesn’t even have to know it exists!
At this point you are probably curious about a few things: Can users override the matching and type whatever they want? What happens if a user’s affiliation is not found in the lookup? And how easy is it to implement this super-cool functionality in my platform?
We’ll address these questions in order:
Can users override the matching? Yes, the system will not prevent them from typing in an affiliation instead of choosing from the list. This is necessary to ensure a smooth submission process and also to allow for rare cases in which the user’s affiliation is not easily found in the lookup. In both of these situations, this is where Dryad’s curation workflow comes into play. A team of curators who go through each data submission will note if the affiliation is not a ROR ID, alter it if there is an existing one, or flag it for the ROR team to investigate and add to their corpus.
Now, how easy is it to implement this functionality in other systems? You can do it right now! Dryad’s code base is open-source and the team is happy to walk you through the implementation of ROR look up and autofill. To discuss the implementation you can get in touch here.
DataCite’s DOI registration system, known as Fabrica, already includes a similar lookup so this is a useful implementation to reference as an example as well.
With the ROR affiliation lookup implemented in Dryad, the future looks bright when it comes to the challenge of identifying research outputs by institution, as every new dataset submitted to Dryad will be associated with a ROR ID. But what about the datasets that are already in Dryad? As you’ll recall from the beginning of our story, affiliation details were not previously collected in Dryad at the time these datasets were submitted. This gap represents the work of approximately 90,000 researchers over the past ten years. The Dryad team wanted to ensure that these datasets had ROR IDs as well, so they teamed up with Ted Habermann (Metadata Game Changers) to identify those missing affiliations. By pulling from open APIs (Crossref, PLOS, Unpaywall, etc) and manually looking up affiliations from related articles, Ted is transforming a corpus of raw affiliations into standardized ROR IDs. Though it is a cumbersome project, this will ultimately allow for Dryad to have an entire database of ROR IDs for all past and future authors publishing their data.
The Dryad-ROR collaboration shows the promise and power of implementing organization IDs in publishing platforms to enable better tracking and discovery of research outputs by institution. We’re excited about this use of ROR and eager to see other platform providers pursue similar implementations in the coming months. Feel free to get in touch with your ideas and questions!
Passing the Torch of Persistence: EZID Development Update
Persistent identifiers are the backbone of scholarly communication infrastructure and long-term digital preservation, key to supporting a fully networked research ecosystem. CDL’s EZID service has been a leading example in the library and research community for how digital curation tools can enable and be enabled by persistent identifiers. The goal of the EZID service was to make the practice of creating and maintaining persistent identifiers, well, easy, and this remains the core feature of EZID to this day.
Achieving persistence with digital objects is a challenge even with a service like EZID. And sadly, achieving persistence with the people behind such services is its own challenge. This week, CDL officially bids farewell (following a transition we announced last year) to EZID’s lead developer, Greg Janée, who is moving on from the system he built ten years ago and has ably maintained over the past decade—a system known not only for making identifier management easy, but also for its reliability, robust API, impeccable documentation, and stellar uptime stats. As the digital curation landscape has been transformed over the years, with new organizations emerging in the identifier space, EZID has been a model of persistence in more ways than one, setting a standard to follow that will be part of Greg’s enduring legacy.
Fortunately for the UC system and for CDL, we will continue to benefit from Greg’s skills and knowledge as he assumes a new position as Director of the UC Santa Barbara Data Curation Program. We know Greg will bring his deep expertise to a broad range of research and preservation activities at UCSB, and we are looking forward to working with him through the networks and collaborations ongoing between UCSB and CDL.
And fortunately for EZID, Greg is passing the torch to another developer, who will be supporting EZID’s valuable services as we move into this new chapter. The EZID team is thrilled to welcome Rushiraj Nenuji, who joined us on May 1 and will be working as our software developer and technical lead.
Rushiraj is based in Santa Barbara and has a 50-50 split appointment between CDL and UCSB, where he is a Science Software Engineer at the National Center for Ecological Analysis and Synthesis (NCEAS). While he has been spending the last 2 months transitioning onto the EZID team, he is no stranger to UC3 as a past contributor to the Make Data Count project, which integrates with the Dash (soon to be Dryad) data publishing service. Rushiraj’s wide experience in front-end and API software engineering, informatics, and open scientific research infrastructure will be an asset for EZID as we pursue new directions and initiatives for the future of CDL’s identifier services portfolio.
Persistence and impermanence will always exist in tandem. And on this note, we bid farewell to Greg and extend a warm welcome to Rushiraj, who will continue the hard work of making identifiers easy and building on Greg’s efforts while exploring new directions for the future.
As always, if you have questions about EZID or about persistent identifiers in general, feel free to contact us at ezid@cdlib.org.